2026/1/7 16:13:56
网站建设
项目流程
眼镜网站 wordpress模板,影楼网站建设,贵阳网站开发zu97,装修设计方案目录Apache ShardingSphere实战1.数据库架构演变与分库分表介绍1.1 海量数据存储问题及解决方案1.2 项目架构的演进1.2.1 理财平台 - V1.01.2.2 理财平台 - V1.x1.2.3 理财平台-V2.0 版本1.2.4 理财平台-V2.x 版本1.5 分库分表1.5.1 什么是分库分表1.5.2 分库分表的方式1.5.2.1…目录Apache ShardingSphere实战1.数据库架构演变与分库分表介绍1.1 海量数据存储问题及解决方案1.2 项目架构的演进1.2.1 理财平台 - V1.01.2.2 理财平台 - V1.x1.2.3 理财平台-V2.0 版本1.2.4 理财平台-V2.x 版本1.5 分库分表1.5.1 什么是分库分表1.5.2 分库分表的方式1.5.2.1 垂直分库1.5.2.2 垂直分表1.5.2.3 水平分库1.5.2.4 水平分表1.5.3 分库分表的规则1.5.4 分库分表带来的问题及解决方案2.ShardingSphere实战2.1 什么是ShardingSphere2.2 Sharding-JDBC介绍2.3 数据分片详解与实战2.3.1 核心概念2.3.1.1 表概念2.3.1.2 分片键2.3.1.3 分片算法2.3.1.4 分片策略2.3.1.5 分布式主键2.3.2 搭建基础环境2.3.2.1 安装环境2.3.2.2 创建数据库和表2.3.2.3 创建SpringBoot程序2) 引入依赖3) 创建实体类4) 创建Mapper2.3.3 实现垂直分库2.3.3.1 配置文件2.3.3.2 垂直分库测试2.3.4 实现水平分表2.3.4.1 数据准备2.3.4.2 配置文件2.3.4.3 测试2.3.4.4 行表达式2.3.4.5 配置分片策略2.3.4.6 分布式序列算法2.3.5 实现水平分库2.3.5.1 数据准备2.3.5.2 配置文件2.3.5.3 水平分库测试2.3.5.4 水平分库查询2.3.5.5 分片算法HASH_MOD和MOD2.3.5.6 水平分库总结2.3.6 实现绑定表2.3.6.1 数据准备2.3.6.2 创建实体类2.3.6.3 创建mapper2.3.6.4 配置多表关联2.3.6.5 测试插入数据2.3.6.6 配置绑定表2.3.6.7 总结2.3.7 实现广播表(公共表)2.3.7.1 公共表介绍2.3.7.2 代码编写2.3.7.3 广播表配置2.3.7.4 测试广播表2.3.7.5 总结2.4 读写分离详解与实战2.4.1 读写分离架构介绍2.4.1.1 读写分离原理2.4.1.2 读写分离应用方案2.4.2 CAP 理论2.4.2.1 CAP理论介绍2.4.2.2 CAP理论特点2.4.2.3 分布式数据库对于CAP理论的实践2.4.3 MySQL主从同步2.4.3.1 主从同步原理2.4.3.2 一主一从架构搭建2.4.4 Sharding-JDBC实现读写分离2.4.4.1 数据准备2.4.4.2 环境准备1) 创建实体类2) 创建Mapper2.4.4.3 配置读写分离2.4.4.4 读写分离测试2.4.4.5 事务读写分离测试2.4.5 负载均衡算法2.4.5.1 一主两从架构2.4.5.2 负载均衡测试2.5 强制路由详解与实战2.5.1 强制路由介绍2.5.2 强制路由的使用2.5.2.1 环境准备2.5.2.2 代码编写2.5.2.3 配置文件2.5.2.4 强制路由到库到表测试2.5.2.5 强制路由到库到表查询测试2.5.2.6 强制路由走主库查询测试2.5.2.7 SQL执行流程剖析2.6 数据加密详解与实战2.6.1 数据加密介绍2.6.2 整体架构2.6.3 加密规则2.6.4 脱敏处理流程2.6.5 数据加密实战2.6.5.1 环境搭建2.6.5.2 加密策略解析2.6.5.3 默认AES加密算法实现2.6.5.4 MD5加密算法实现2.7 分布式事务详解与实战2.7.1 什么是分布式事务2.7.1.1 本地事务介绍2.7.1.2 事务日志undo和redo2.7.1.3 分布式事务介绍2.7.2 分布式事务理论2.7.2.1 CAP (强一致性)2.7.2.2 BASE最终一致性2.7.3 分布式事务模式大概了解2.7.3.1 DTP模型与XA协议2.7.3.2 2PC模式 (强一致性)2.7.3.3 TCC模式 (最终一致性)2.7.3.4 消息队列模式最终一致性2.7.3.5 AT模式 (最终一致性)2.7.3.6 Saga模式最终一致性2.7.4 Sharding-JDBC分布式事务实战2.7.4.1 Sharding-JDBC分布式事务介绍2.7.4.2 环境准备2.7.4.3 案例实现2.7.4.4 案例测试2.8 ShardingProxy实战2.8.1 使用二进制发布包安装ShardingSphere-Proxy2.8.2 proxy实现读写分离2.8.3 使用应用程序连接proxy2.8.4 Proxy实现垂直分片2.8.5 Proxy实现水平分片2.8.6 Proxy实现广播表2.8.7 Proxy实现绑定表2.8.8 总结Apache ShardingSphere实战1.数据库架构演变与分库分表介绍1.1 海量数据存储问题及解决方案如今随着互联网的发展数据的量级也是成指数的增长从GB到TB到PB。对数据的各种操作也是愈加的困难传统单体的关系性数据库已经无法满足快速查询与插入数据的需求。阿里数据中心内景( 阿里、百度、腾讯这样的互联网巨头数据量据说已经接近EB级)事务安全性,NOSQL数据库对事务的支持不完善. MySQL不可替代.遇到的问题用户请求量大单库的数据量过大单表的数据量过大解决方案单机数据库 -- 主从架构 — 分库分表1.2 项目架构的演进1.2.1 理财平台 - V1.0此时项目是一个单体应用架构 (一个归档包可以是JAR、WAR、EAR或其它归档格式包含所有功能的应用程序通常称为单体应用)这个阶段是公司发展的早期阶段系统架构如上图所示。我们经常会在单台服务器上运行我们所有的程序和软件。在项目运行初期User表、Order表、等等各种表都在同一个数据库中每个表都包含了大量的字段。在用户量比较少访问量也比较少的时候单库单表不存在问题。这个阶段一般是属于业务规模不是很大的公司使用因为机器都是单台的话随着我们业务规模的增长慢慢的我们的网站就会出现一些瓶颈和隐患问题1.2.2 理财平台 - V1.x随着访问量的继续不断增加单台应用服务器已经无法满足我们的需求。所以我们通过增 加应用服务器的方式来将服务器集群化。存在的问题采用了应用服务器高可用集群的架构之后,应用层的性能被我们拉上来了,但是数据库的负载也在增加,随着访问量的提高,所有的压力都将集中在数据库这一层.1.2.3 理财平台-V2.0 版本应用层的性能被我们拉上来了但数据库的负载也在逐渐增大那如何去提高数据库层面的性能呢数据库主从复制、读写分离写10000 - 3分钟, 读10000-5秒, 读操作占整体操作8成,写操作2成读写分离的数据节点中的数据内容是一致。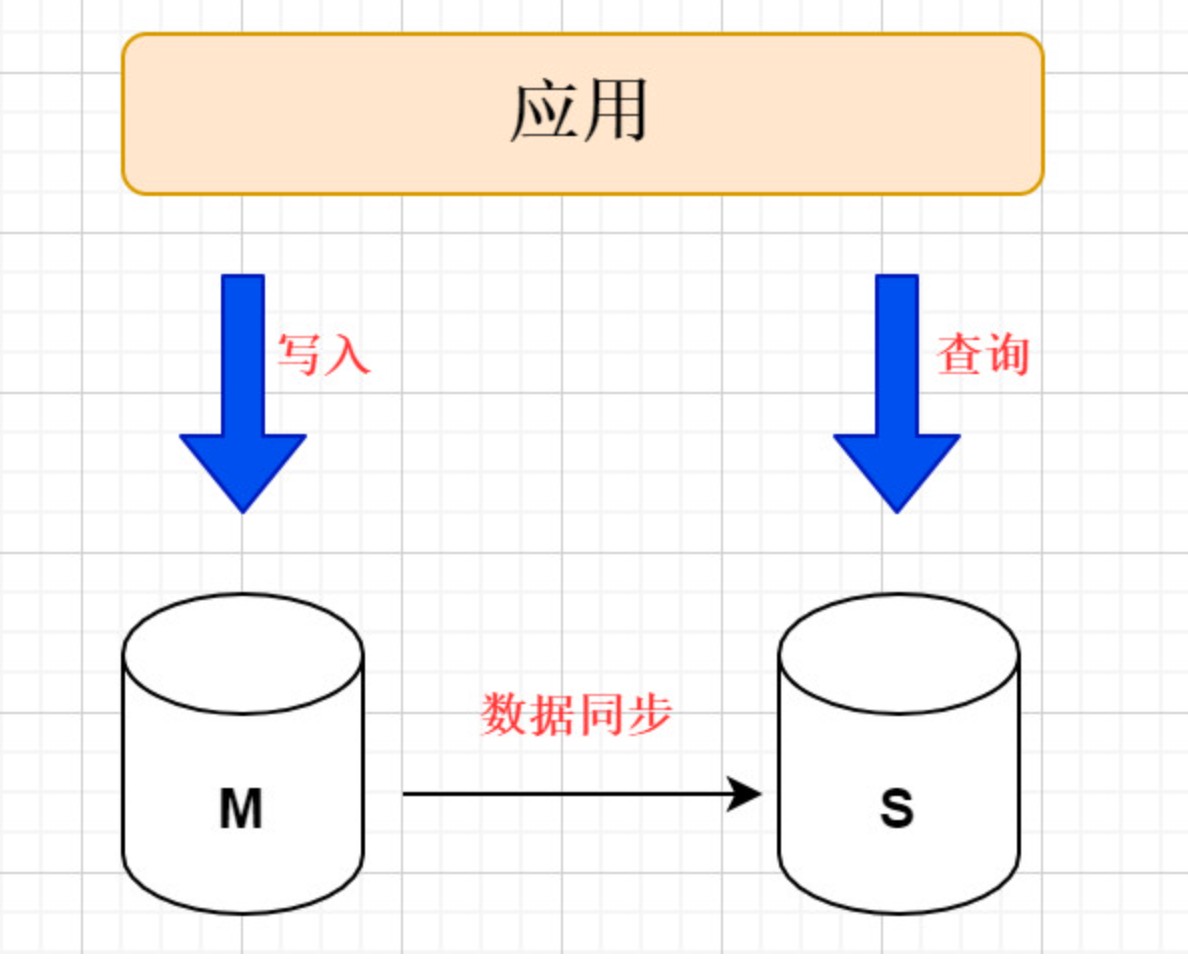使用主从复制读写分离一定程度上可以解决问题但是随着用户量的增加、访问量的增加、数据量的增加依然会带来大量的问题.1.2.4 理财平台-V2.x 版本随着访问量的持续不断增加慢慢的我们的系统项目会出现许多用户访问同一内容的情况比如秒杀活动抢购活动等。那么对于这些热点数据的访问没必要每次都从数据库重读取这时我们可以使用到缓存技术比如 redis、memcache 来作为我们应用层的缓存。数据库主从复制、读写分离 缓存技术存在的问题缓存只能缓解读取压力数据库的写入压力还是很大且随着数据量的继续增大性能还是很缓慢我们的系统架构从单机演变到这个阶,所有的数据都还在同一个数据库中尽管采取了增加缓存主从、读写分离的方式但是随着数据库的压力持续增加数据库的瓶颈仍然是个最大的问题。因此我们可以考虑对数据的垂直拆分和水平拆分。就是今天所讲的主题分库分表。1.5 分库分表1.5.1 什么是分库分表简单来说就是指通过某种特定的条件将我们存放在同一个数据库中的数据分散存放到多个数据库主机上面以达到分散单台设备负载的效果。分库分表解决的问题 ?什么情况下需要分库分表1.5.2 分库分表的方式分库分表包括 垂直分库、垂直分表、水平分库、水平分表 四种方式。1.5.2.1 垂直分库数据库中不同的表对应着不同的业务垂直切分是指按照业务的不同将表进行分类,分布到不同的数据库上面将数据库部署在不同服务器上从而达到多个服务器共同分摊压力的效果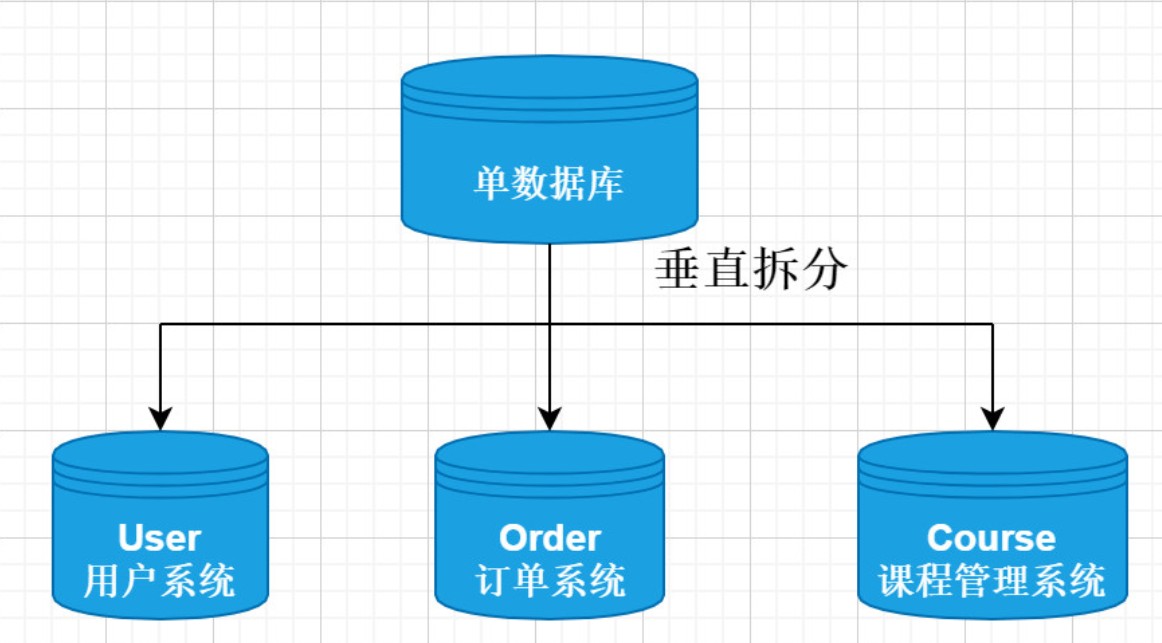1.5.2.2 垂直分表表中字段太多且包含大字段的时候在查询时对数据库的IO、内存会受到影响同时更新数据时产生的binlog文件会很大MySQL在主从同步时也会有延迟的风险将一个表按照字段分成多表每个表存储其中一部分字段。对职位表进行垂直拆分, 将职位基本信息放在一张表, 将职位描述信息存放在另一张表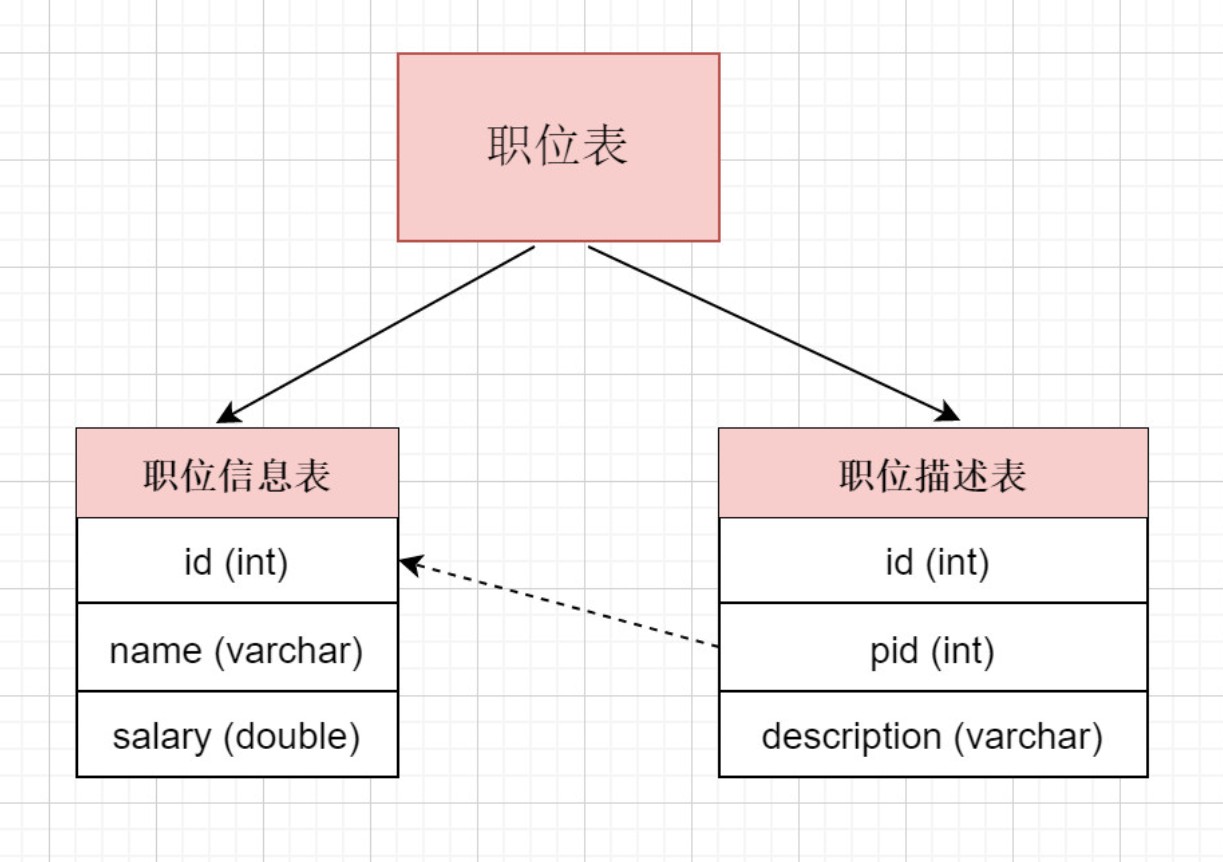垂直拆分带来的一些提升解决业务层面的耦合业务清晰能对不同业务的数据进行分级管理、维护、监控、扩展等高并发场景下垂直分库一定程度的提高访问性能垂直拆分没有彻底解决单表数据量过大的问题1.5.2.3 水平分库将单张表的数据切分到多个服务器上去每个服务器具有相应的库与表只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力突破IO、连接数、硬件资源等的瓶颈.简单讲就是根据表中的数据的逻辑关系将同一个表中的数据按照某种条件拆分到多台数据库主机上面, 例如将订单表 按照id是奇数还是偶数, 分别存储在不同的库中。1.5.2.4 水平分表针对数据量巨大的单张表比如订单表按照规则把一张表的数据切分到多张表里面去。 但是这些表还是在同一个库中所以库级别的数据库操作还是有IO瓶颈。总结水平根据数据进行拆分- **垂直分表**: 将一个表按照字段分成多表每个表存储其中一部分字段。 - **垂直分库**: 根据表的业务不同,分别存放在不同的库中,这些库分别部署在不同的服务器. - **水平分库**: 把一张表的数据按照一定规则,分配到**不同的数据库**,每一个库只有这张表的部分数据. - **水平分表**: 把一张表的数据按照一定规则,分配到**同一个数据库的多张表中**,每个表只有这个表的部分数据.1.5.3 分库分表的规则1) 水平分库规则不跨库、不跨表保证同一类的数据都在同一个服务器上面。数据在切分之前需要考虑如何高效的进行数据获取如果每次查询都要跨越多个节点就需要谨慎使用。2) 水平分表规则RANGE时间按照年、月、日去切分。地域按照省或市去切分。大小从0到1000000一个表。HASH用户ID取模3) 不同的业务使用的切分规则是不一样就上面提到的切分规则举例如下用户表范围法以用户ID为划分依据将数据水平切分到两个数据库实例如1到1000W在一张表1000W到2000W在一张表这种情况会出现单表的负载较高按照用户ID HASH尽量保证用户数据均衡分到数据库中流水表时间维度可以根据每天新增的流水来判断选择按照年份分库还是按照月份分库甚至也可以按照日期分库1.5.4 分库分表带来的问题及解决方案关系型数据库在单机单库的情况下,比较容易出现性能瓶颈问题,分库分表可以有效的解决这方面的问题,但是同时也会产生一些 比较棘手的问题.1) 事务一致性问题当我们需要更新的内容同时分布在不同的库时, 不可避免的会产生跨库的事务问题. 原来在一个数据库操作, 本地事务就可以进行控制, 分库之后 一个请求可能要访问多个数据库,如何保证事务的一致性,目前还没有简单的解决方案.2) 跨节点关联的问题在分库之后, 原来在一个库中的一些表,被分散到多个库,并且这些数据库可能还不在一台服务器,无法关联查询.解决这种关联查询,需要我们在代码层面进行控制,将关联查询拆开执行,然后再将获取到的结果进行拼装.3) 分页排序查询的问题分库并行查询时,如果用到了分页 每个库返回的结果集本身是无序的, 只有将多个库中的数据先查出来,然后再根据排序字段在内存中进行排序,如果查询结果过大也是十分消耗资源的.4) 主键避重问题在分库分表的环境中,表中的数据存储在不同的数据库, 主键自增无法保证ID不重复, 需要单独设计全局主键.5) 公共表的问题不同的数据库,都需要从公共表中获取数据. 某一个数据库更新看公共表其他数据库的公共表数据需要进行同步.上面我们说了分库分表后可能会遇到的一些问题, 接下来带着这些问题,我们就来一起来学习一下Apache ShardingSphere !2.ShardingSphere实战2.1 什么是ShardingSphereApache ShardingSphere 是一款分布式的数据库生态系统 可以将任意数据库转换为分布式数据库并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。官网: https://shardingsphere.apache.org/document/current/cn/overview/Apache ShardingSphere 设计哲学为 Database Plus旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力而并非实现一个全新的数据库。 它站在数据库的上层视角关注它们之间的协作多于数据库自身。Apache ShardingSphere它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar规划中这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。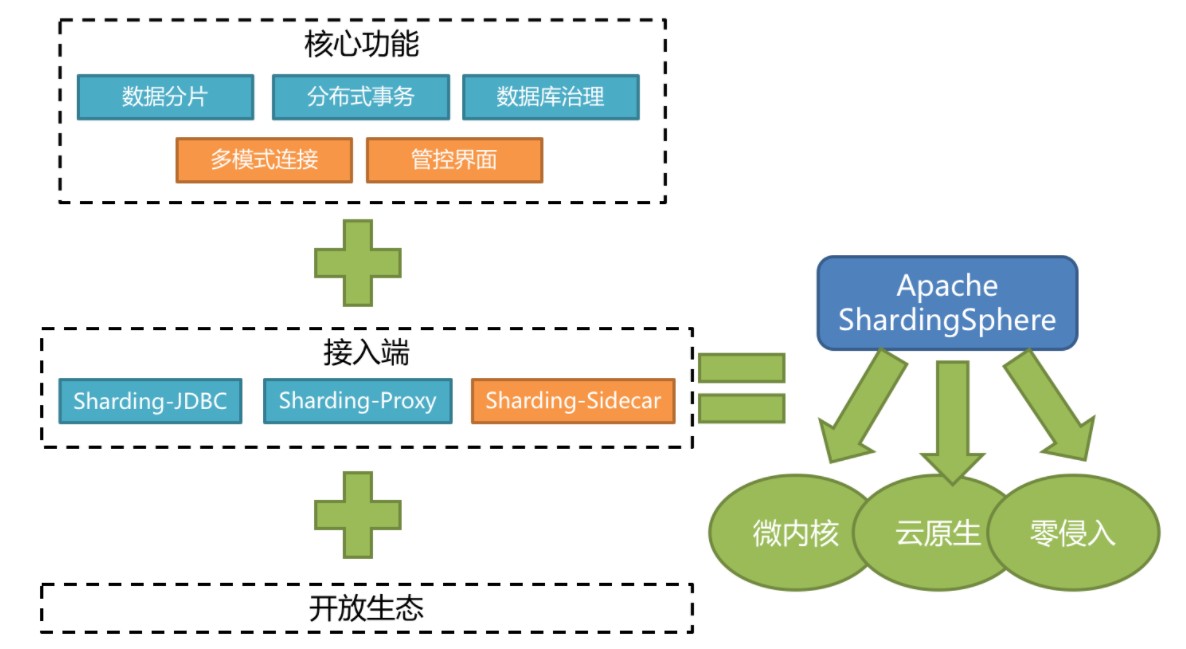Sharding-JDBC被定位为轻量级Java框架在Java的JDBC层提供的额外服务以jar包形式使用。Sharding-Proxy被定位为透明化的数据库代理端向应用程序完全透明可直接当做 MySQL 使用Sharding-Sidecar被定位为Kubernetes(K8S)的云原生数据库代理以守护进程的形式代理所有对数据库的访问(只是计划在未来做)。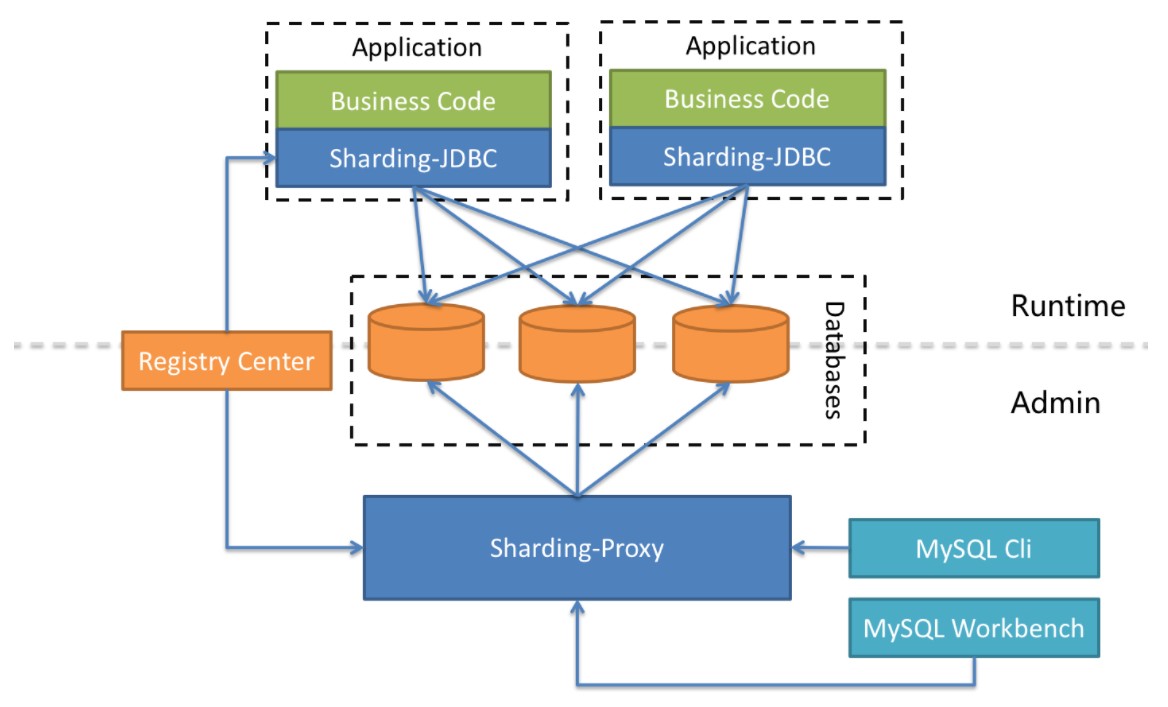Sharding-JDBC、Sharding-Proxy之间的区别如下Sharding-JDBCSharding-Proxy数据库任意MySQL/PostgreSQL连接消耗数高低异构语言仅Java任意性能损耗低损耗略高无中心化是否静态入口无有异构是继面向对象编程思想又一种较新的编程思想面向服务编程不用顾虑语言的差别提供规范的服务接口我们无论使用什么语言就都可以访问使用了大大提高了程序的复用率。Sharding-Proxy的优势在于对异构语言的支持以及为DBA提供可操作入口。它可以屏蔽底层分库分表的复杂度运维及开发人员仅面向proxy操作像操作单个数据库一样操作复杂的底层MySQL实例很显然ShardingJDBC只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有分库分表逻辑均有业务方自己控制,所以他的功能相对灵活,支持的 数据库也非常多,但是对业务侵入大,需要业务方自己定义所有的分库分表逻辑.而ShardingProxy是一个独立部署的服务,对业务方无侵入,业务方可以像用一个普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,但是这也意味着功能会比较固定,能够支持的数据库也比较少,两者各有优劣.ShardingSphere项目状态如下ShardingSphere定位为关系型数据库中间件旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力而并非实现一个全新的关系型数据库。2.2 Sharding-JDBC介绍Sharding-JDBC定位为轻量级Java框架在Java的JDBC层提供的额外服务。 它使用客户端直连数据库以jar包形式提供服务无需额外部署和依赖可理解为增强版的JDBC驱动完全兼容JDBC和各种ORM框架的使用。适用于任何基于Java的ORM框架如JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。基于任何第三方的数据库连接池如DBCP, C3P0, Druid, HikariCP等。支持任意实现JDBC规范的数据库。目前支持MySQLOracleSQLServer和PostgreSQL。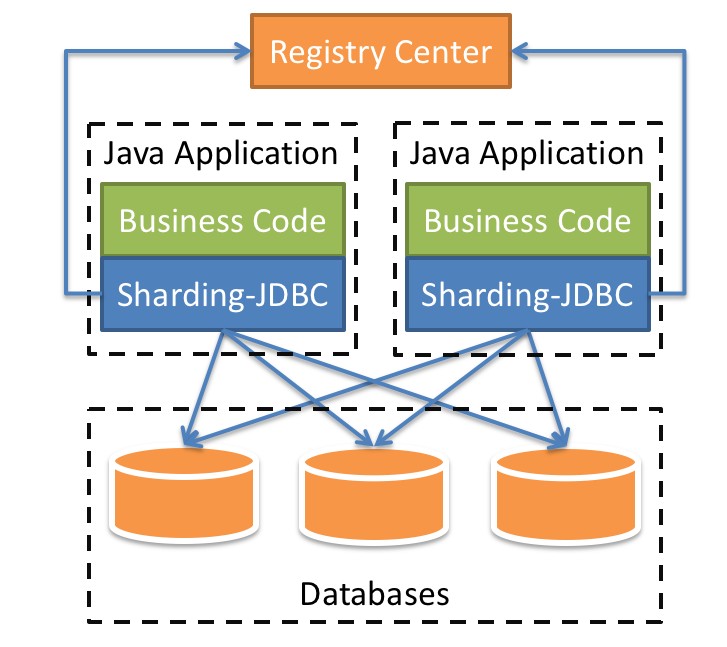Sharding-JDBC主要功能数据分片分库分表读写分离分片策略分布式主键分布式事务标准化事务接口XA强一致性事务柔性事务数据库治理配置动态化编排治理数据脱敏可视化链路追踪Sharding-JDBC 内部结构图中黄色部分表示的是Sharding-JDBC的入口API采用工厂方法的形式提供。 目前有ShardingDataSourceFactory和MasterSlaveDataSourceFactory两个工厂类。ShardingDataSourceFactory支持分库分表、读写分离操作MasterSlaveDataSourceFactory支持读写分离操作图中蓝色部分表示的是Sharding-JDBC的配置对象提供灵活多变的配置方式。 ShardingRuleConfiguration是分库分表配置的核心和入口它可以包含多个TableRuleConfiguration和MasterSlaveRuleConfiguration。TableRuleConfiguration封装的是表的分片配置信息有5种配置形式对应不同的Configuration类型。MasterSlaveRuleConfiguration封装的是读写分离配置信息。图中红色部分表示的是内部对象由Sharding-JDBC内部使用应用开发者无需关注。Sharding-JDBC通过ShardingRuleConfiguration和MasterSlaveRuleConfiguration生成真正供ShardingDataSource和MasterSlaveDataSource使用的规则对象。ShardingDataSource和MasterSlaveDataSource实现了DataSource接口是JDBC的完整实现方案。2.3 数据分片详解与实战2.3.1 核心概念对于数据库的垂直拆分一般都是在数据库设计初期就会完成,因为垂直拆分与业务直接相关,而我们提到的分库分表一般是指的水平拆分,数据分片就是将原本一张数据量较大的表t_order拆分生成数个表结构完全一致的小数据量表t_order_0、t_order_1…,每张表只保存原表的部分数据.2.3.1.1 表概念逻辑表水平拆分的数据库表的相同逻辑和数据结构表的总称。 比如的订单表 t_order — t_order_0 …t_order _9.拆分后t_order表 已经不存在了,这个时候t_order表就是上面拆分的表单的逻辑表.真实表数据库中真实存在的物理表。 t_order_0 …t_order _9数据节点在分片之后由数据源和数据表组成。比如: t_order_db1.t_order_0绑定表绑定表是指具有相同分片规则的一组关联表如主表与子表例如t_order与t_order_item均按order_id进行分片。当这些表中order_id相同的数据落在相同的分片上时它们即构成绑定表关系。绑定表之间的多表关联查询不会产生笛卡尔积从而显著提升查询效率。# t_ordert_order0、t_order1# t_order_itemt_order_item0、t_order_item1select*fromt_order ojoint_order_item iono.order_idi.order_idwhereo.order_idin(10,11);由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系会出现笛卡尔积关联查询将产生如下四条SQL。select*fromt_order0 ojoint_order_item0 iono.order_idi.order_idwhereo.order_idin(10,11);select*fromt_order0 ojoint_order_item1 iono.order_idi.order_idwhereo.order_idin(10,11);select*fromt_order1 ojoint_order_item0 iono.order_idi.order_idwhereo.order_idin(10,11);select*fromt_order1 ojoint_order_item1 iono.order_idi.order_idwhereo.order_idin(10,11);如果配置绑定表关系后再进行关联查询时只要对应表分片规则一致产生的数据就会落到同一个库中那么只需 t_order_0和 t_order_item_0 表关联即可。select*fromt_order0 ojoint_order_item0 iono.order_idi.order_idwhereo.order_idin(10,11);select*fromt_order1 ojoint_order_item1 iono.order_idi.order_idwhereo.order_idin(10,11);广播表在使用中有些表没必要做分片例如字典表、省份信息等因为他们数据量不大而且这种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储存储的表结构和数据完全相同。单表指所有的分片数据源中只存在唯一一张的表。适用于数据量不大且不需要做任何分片操作的场景。2.3.1.2 分片键用于分片的数据库字段是将数据库表水平拆分的关键字段。例将订单表中的订单主键取模分片则订单主键为分片字段。 SQL 中如果无分片字段将执行全路由(去查询所有的真实表)性能较差。 除了对单分片字段的支持Apache ShardingSphere 也支持根据多个字段进行分片。2.3.1.3 分片算法由于分片算法(ShardingAlgorithm) 和业务实现紧密相关因此并未提供内置分片算法而是通过分片策略将各种场景提炼出来提供更高层级的抽象并提供接口让应用开发者自行实现分片算法。目前提供4种分片算法。精确分片算法用于处理使用单一键作为分片键的与IN进行分片的场景。范围分片算法用于处理使用单一键作为分片键的BETWEEN AND、、、、进行分片的场景。复合分片算法用于处理使用多键作为分片键进行分片的场景多个分片键的逻辑较复杂需要应用开发者自行处理其中的复杂度。Hint分片算法Hint 分片算法适用于分片键无法从 SQL 语句中直接获取而需依赖外部上下文如用户身份、会话信息等动态确定的场景。当数据库表结构中不包含实际用于分片的字段时可通过 SQL Hint 在执行时显式传递分片值从而实现精确的数据路由。典型应用场景包括内部系统按员工登录 ID 进行分库但业务表中并未存储该字段。此时借助 Hint 机制可在不修改表结构的前提下完成分片逻辑。2.3.1.4 分片策略分片策略(ShardingStrategy) 包含分片键和分片算法真正可用于分片操作的是分片键 分片算法也就是分片策略。目前提供5种分片策略。标准分片策略 StandardShardingStrategy只支持单分片键提供对SQL语句中的, , , , , IN和BETWEEN AND的分片操作支持。提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的RangeShardingAlgorithm是可选的。但是SQL中使用了范围操作如果不配置RangeShardingAlgorithm会采用全库路由扫描效率低。复合分片策略 ComplexShardingStrategy支持多分片键。提供对SQL语句中的, , , , , IN和BETWEEN AND的分片操作支持。由于多分片键之间的关系复杂因此并未进行过多的封装而是直接将分片键值组合以及分片操作符透传至分片算法完全由应用开发者实现提供最大的灵活度。行表达式分片策略 InlineShardingStrategy只支持单分片键。使用Groovy的表达式提供对SQL语句中的和IN的分片操作支持对于简单的分片算法可以通过简单的配置使用从而避免繁琐的Java代码开发。如: t_user_$-{u_id % 8} 表示t_user表根据u_id模8而分成8张表表名称为t_user_0到t_user_7。Hint分片策略HintShardingStrategy通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。不分片策略NoneShardingStrategy不分片的策略。2.3.1.5 分布式主键数据分片后不同数据节点生成全局唯一主键是非常棘手的问题同一个逻辑表t_order内的不同真实表t_order_n之间的自增键由于无法互相感知而产生重复主键。尽管可通过设置自增主键初始值和步长的方式避免ID碰撞但这样会使维护成本加大缺乏完整性和可扩展性。如果后期需要增加分片表的数量要逐一修改分片表的步长运维成本非常高所以不建议这种方式。ShardingSphere不仅提供了内置的分布式主键生成器例如UUID、SNOWFLAKE还抽离出分布式主键生成器的接口方便用户自行实现自定义的自增主键生成器。内置主键生成器UUID采用UUID.randomUUID()的方式产生分布式主键。SNOWFLAKE在分片规则配置模块可配置每个表的主键生成策略默认使用雪花算法生成64bit的长整型数据。2.3.2 搭建基础环境2.3.2.1 安装环境jdk: 要求jdk必须是1.8版本及以上MySQL: 推荐mysql5.7版本搭建两台MySQL服务器mysql-server1 192.168.116.128 mysql-server2 192.168.116.1292.3.2.2 创建数据库和表在mysql01服务器上, 创建数据库 payorder_db,并创建表pay_orderCREATEDATABASEpayorder_dbCHARACTERSETutf8;CREATETABLEpay_order(order_idbigint(20)NOTNULLAUTO_INCREMENT,user_idint(11)DEFAULTNULL,product_namevarchar(128)DEFAULTNULL,COUNTint(11)DEFAULTNULL,PRIMARYKEY(order_id))ENGINEInnoDBAUTO_INCREMENT12345679DEFAULTCHARSETutf8在mysql02服务器上, 创建数据库 user_db,并创建表usersCREATEDATABASEuser_dbCHARACTERSETutf8;CREATETABLEusers(idint(11)NOTNULL,usernamevarchar(255)NOTNULLCOMMENT用户昵称,phonevarchar(255)NOTNULLCOMMENT注册手机,PASSWORDvarchar(255)DEFAULTNULLCOMMENT用户密码,PRIMARYKEY(id))ENGINEInnoDBDEFAULTCHARSETutf8COMMENT用户表2.3.2.3 创建SpringBoot程序1) 创建项目环境说明SpringBoot2.3.7MyBatisPlusShardingSphere-JDBC 5.1HikariMySQL 5.7Spring脚手架: http://start.aliyun.com2) 引入依赖parentgroupIdorg.springframework.boot/groupIdartifactIdspring-boot-starter-parent/artifactIdversion2.3.7.RELEASE/versionrelativePath//parentdependenciesdependencygroupIdorg.springframework.boot/groupIdartifactIdspring-boot-starter-web/artifactId/dependencydependencygroupIdorg.apache.shardingsphere/groupIdartifactIdshardingsphere-jdbc-core-spring-boot-starter/artifactIdversion5.1.1/version/dependencydependencygroupIdcom.baomidou/groupIdartifactIdmybatis-plus-boot-starter/artifactIdversion3.3.1/version/dependencydependencygroupIdmysql/groupIdartifactIdmysql-connector-java/artifactIdscoperuntime/scope/dependencydependencygroupIdorg.projectlombok/groupIdartifactIdlombok/artifactId/dependencydependencygroupIdorg.springframework.boot/groupIdartifactIdspring-boot-starter-test/artifactIdscopetest/scopeexclusionsexclusiongroupIdorg.junit.vintage/groupIdartifactIdjunit-vintage-engine/artifactId/exclusion/exclusions/dependency/dependencies3) 创建实体类TableName(pay_order)//逻辑表名DataToStringpublicclassPayOrder{TableIdprivatelongorder_id;privatelonguser_id;privateStringproduct_name;privateintcount;}TableName(users)DataToStringpublicclassUser{TableIdprivatelongid;privateStringusername;privateStringphone;privateStringpassword;}4) 创建MapperMapperpublicinterfacePayOrderMapperextendsBaseMapperPayOrder{}MapperpublicinterfaceUserMapperextendsBaseMapperUser{}2.3.3 实现垂直分库2.3.3.1 配置文件使用sharding-jdbc 对数据库中水平拆分的表进行操作,通过sharding-jdbc对分库分表的规则进行配置,配置内容包括数据源、主键生成策略、分片策略等。application.properties基础配置# 应用名称 spring.application.nameshardingsphere-jdbc-table数据源# 应用名称 spring.application.nameshardingsphere-jdbc-table # 定义多个数据源 spring.shardingsphere.datasource.names db1,db2 #数据源1 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.128:3306/payorder_db?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #数据源2 spring.shardingsphere.datasource.db2.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db2.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db2.url jdbc:mysql://192.168.116.129:3306/user_db?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db2.username root spring.shardingsphere.datasource.db2.password 123456 #配置数据节点 # 标准分片表配置 # 由数据源名 表名组成以小数点分隔。多个表以逗号分隔支持 inline 表达式。 spring.shardingsphere.rules.sharding.tables.pay_order.actual-data-nodesdb1.pay_order spring.shardingsphere.rules.sharding.tables.users.actual-data-nodesdb2.users mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl配置数据节点# 标准分片表配置 # 由数据源名 表名组成以小数点分隔。多个表以逗号分隔支持 inline 表达式。 spring.shardingsphere.rules.sharding.tables.pay_order.actual-data-nodesdb1.pay_order spring.shardingsphere.rules.sharding.tables.users.actual-data-nodesdb2.users打开sql输出日志mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl2.3.3.2 垂直分库测试SpringBootTestclassShardingJdbcApplicationTests{AutowiredprivateUserMapperuserMapper;AutowiredprivatePayOrderMapperpayOrderMapper;TestpublicvoidtestInsert(){UserusernewUser();user.setId(1002);user.setUsername(大远哥);user.setPhone(15612344321);user.setPassword(123456);userMapper.insert(user);PayOrderpayOrdernewPayOrder();payOrder.setOrder_id(12345679);payOrder.setProduct_name(猕猴桃);payOrder.setUser_id(user.getId());payOrder.setCount(2);payOrderMapper.insert(payOrder);}TestpublicvoidtestSelect(){UseruseruserMapper.selectById(1001);System.out.println(user);PayOrderpayOrderpayOrderMapper.selectById(12345678);System.out.println(payOrder);}}数据插入情况可以看到User数据就插入到了129的服务器PayOrder数据就插入到了128服务器。这就实现了一个简单的垂直分库的情况不同的表分布在不同的服务器上2.3.4 实现水平分表2.3.4.1 数据准备需求说明:在mysql-server01服务器上, 创建数据库 course_db创建表 t_course_1 、 t_course_2约定规则如果添加的课程 id 为偶数添加到 t_course_1 中奇数添加到 t_course_2 中。水平分片的id需要在业务层实现不能依赖数据库的主键自增CREATETABLEt_course_1(cidBIGINT(20)NOTNULL,user_idBIGINT(20)DEFAULTNULL,cnameVARCHAR(50)DEFAULTNULL,briefVARCHAR(50)DEFAULTNULL,priceDOUBLEDEFAULTNULL,statusINT(11)DEFAULTNULL,PRIMARYKEY(cid))ENGINEINNODBDEFAULTCHARSETutf8CREATETABLEt_course_2(cidBIGINT(20)NOTNULL,user_idBIGINT(20)DEFAULTNULL,cnameVARCHAR(50)DEFAULTNULL,briefVARCHAR(50)DEFAULTNULL,priceDOUBLEDEFAULTNULL,statusINT(11)DEFAULTNULL,PRIMARYKEY(cid))ENGINEINNODBDEFAULTCHARSETutf82.3.4.2 配置文件1) 基础配置# 应用名称 spring.application.namesharding-jdbc # 打印SQl spring.shardingsphere.props.sql-showtrue2) 数据源配置#数据源配置 #配置真实的数据源 spring.shardingsphere.datasource.namesdb1 #数据源1 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.128:3306/course_db?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 1234563) 数据节点配置先指定t_course_1表试试#1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb1.t_course_14) 完整配置文件# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db1 #数据源1 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.128:3306/course_db?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #配置数据节点 # 标准分片表配置 # 由数据源名 表名组成以小数点分隔。多个表以逗号分隔支持 inline 表达式。 spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb1.t_course_1 mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl2.3.4.3 测试course类TableName(t_course)DataToStringpublicclassCourseimplementsSerializable{TableIdprivateLongcid;privateLonguserId;privateStringcname;privateStringbrief;privatedoubleprice;privateintstatus;}CourseMapperMapperpublicinterfaceCourseMapperextendsBaseMapperCourse{}//水平分表测试AutowiredprivateCourseMappercourseMapper;TestpublicvoidtestInsertCourse(){for(inti0;i3;i){CoursecoursenewCourse();course.setCid(10086Li);course.setUserId(1Li);course.setCname(Java经典面试题讲解);course.setBrief(课程涵盖目前最容易被问到的10000道Java面试题);course.setPrice(100.0);course.setStatus(1);courseMapper.insert(course);}}插入数据情况2.3.4.4 行表达式对上面的配置操作进行修改, 使用inline表达式,灵活配置数据节点行表达式的使用: https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/inline-expression/)spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb1.t_course_$-{1..2}表达式db1.t_course_$-{1..2}$ 会被 大括号中的 {1..2} 所替换, ${begin..end} 表示范围区间 会有两种选择: **db1.t_course_1** 和 **db1.t_course_2**2.3.4.5 配置分片策略分片策略包括分片键和分片算法.分片规则,约定cid值为偶数时,添加到t_course_1表如果cid是奇数则添加到t_course_2表配置分片策略#1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb1.t_course_$-{1..2} ##2.配置分片策略(分片策略包括分片键和分片算法) #2.1 分片键名称: cid spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid #2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nametable-inline #2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含-行表达式分片算法) spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.typeINLINE #2.4 分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expressiont_course_$-{cid % 2 1}测试完整配置文件# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db1 #数据源1 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.128:3306/course_db?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb1.t_course_$-{1..2} ##2.配置分片策略(分片策略包括分片键和分片算法) #2.1 分片键名称: cid spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid #2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nametable-inline #2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含-行表达式分片算法) spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.typeINLINE #2.4 分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expressiont_course_$-{cid % 2 1} mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImplTestpublicvoidtestInsertCourse(){for(inti0;i20;i){CoursecoursenewCourse();course.setCid(10086Li);course.setUserId(1Li);course.setCname(Java经典面试题讲解);course.setBrief(课程涵盖目前最容易被问到的10000道Java面试题);course.setPrice(100.0);course.setStatus(1);courseMapper.insert(course);}}数据分布情况2.3.4.6 分布式序列算法在水平分表中由于数据会存储到多个表中每个表有独立的主键也就是说有可能会发生主键重复的情况所以就不能使用MySQL默认的主键自增应该使用分布式ID作为主键值确保每个主键都是唯一的雪花算法https://shardingsphere.apache.org/document/5.1.1/cn/features/sharding/concept/key-generator/水平分片需要关注全局序列因为不能简单的使用基于数据库的主键自增。这里有两种方案一种是基于MyBatisPlus的id策略一种是ShardingSphere-JDBC的全局序列配置。基于MyBatisPlus的id策略将Course类的id设置成如下形式TableName(t_course)DataToStringpublicclassCourseimp{TableId(valuecid,typeIdType.ASSIGN_ID)privateLongcid;privateLonguserId;privateStringcname;privateStringbrief;privatedoubleprice;privateintstatus;}基于ShardingSphere-JDBC的全局序列配置和前面的MyBatisPlus的策略二选一#3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.columncid #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-namealg_snowflake #3.3 分布式序列-算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.typeSNOWFLAKE # 分布式序列算法属性配置,可以先不配置 #spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.xxx此时需要将实体类中的id策略修改成以下形式//当配置了shardingsphere-jdbc的分布式序列时自动使用shardingsphere-jdbc的分布式序列//当没有配置shardingsphere-jdbc的分布式序列时自动依赖数据库的主键自增策略TableId(typeIdType.AUTO)测试TestpublicvoidtestInsertCourse(){for(inti0;i20;i){CoursecoursenewCourse();course.setUserId(1Li);course.setCname(Java经典面试题讲解);course.setBrief(课程涵盖目前最容易被问到的10000道Java面试题);course.setPrice(100.0);course.setStatus(1);courseMapper.insert(course);}}2.3.5 实现水平分库水平分库是把同一个表的数据按一定规则拆到不同的数据库中每个库可以放在不同的服务器上。接下来看一下如何使用Sharding-JDBC实现水平分库2.3.5.1 数据准备创建数据库在mysql-server01服务器上, 创建数据库 course_db0, 在mysql-server02服务器上, 创建数据库 course_db1分别在course_db0和course_db1中创建表t_course_0CREATETABLEt_course_0(cidbigint(20)NOTNULL,user_idbigint(20)DEFAULTNULL,corder_nobigint(20)DEFAULTNULL,cnamevarchar(50)DEFAULTNULL,briefvarchar(50)DEFAULTNULL,pricedoubleDEFAULTNULL,statusint(11)DEFAULTNULL,PRIMARYKEY(cid))ENGINEInnoDBDEFAULTCHARSETutf8实体类原有的Course类添加一个corder_no即可.如果使用了ShardingJDBC的分布式序列ShardingJDBC会自动生成id如果没有配置就自动依赖mybatisplus设置的主键自增IdType.AUTOTableName(t_course)DataToStringpublicclassCourseimplementsSerializable{TableId(valuecid,typeIdType.AUTO)privateLongcid;privateLonguserId;privateLongcorderNo;privateStringcname;privateStringbrief;privatedoubleprice;privateintstatus;}2.3.5.2 配置文件1) 数据源配置# 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/course_db0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/course_db1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 1234562) 数据节点配置先测试水平分库, 数据节点中数据源是动态的, 数据表固定为t_course_0, 方便测试db$-{0…1}.t_course_0表示数据库是动态的db由db0、db1组成表就是t_course_0一个表spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb$-{0..1}.t_course_03) 水平分库之分库策略配置分库策略: 以user_id为分片键分片策略为user_id % 2user_id为偶数操作db0数据源否则操作db1数据源。#水平分库-分库策略 ##2.配置分片策略(分片策略包括分片键和分片算法) #2.1 分片键名称: user_id spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-columnuser_id #2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-nametable-inline #2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含-行表达式分片算法) spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.typeINLINE #2.4 分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expressiondb$-{user_id % 2}4) 分布式主键自增#3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.columncid #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-namealg_snowflake #3.3 分布式序列-算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.typeSNOWFLAKE5) 测试完成配置文件# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/course_db0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/course_db1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb$-{0..1}.t_course_0 ##2.配置分片策略(分片策略包括分片键和分片算法) #2.1 分片键名称: user_id spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-columnuser_id #2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-nametable-inline #2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含-行表达式分片算法) spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.typeINLINE #2.4 分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expressiondb$-{user_id % 2} #3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.columncid #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-namealg_snowflake #3.3 分布式序列-算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.typeSNOWFLAKE mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl/** * 水平分库 -- 分库插入数据 */TestpublicvoidtestInsertCourseDB(){for(inti0;i10;i){CoursecoursenewCourse();course.setUserId(1001Li);course.setCname(Java经典面试题讲解);course.setBrief(课程涵盖目前最容易被问到的10000道Java面试题);course.setPrice(100.0);course.setStatus(1);courseMapper.insert(course);}}数据分布情况可以看到偶数都分布到了course_db0上6) 水平分库之分表策略配置可以分库和分表的分片策略同时设置分库规则以user_id为分片键分片策略为user_id % 2user_id为偶数操作db0数据源否则操作db1数据源。分表规则t_course表中cid的哈希值为偶数时数据插入对应服务器的t_course_0表cid的哈希值为奇数时数据插入对应服务器的t_course_1。修改数据节点配置,数据落地到dn0或db1数据源的 t_course_0表 或者 t_course_1表.spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb$-{0..1}.t_course_$-{0..1}分别在两个库中再创建一个t_course_1表CREATETABLEt_course_1(cidbigint(20)NOTNULL,user_idbigint(20)DEFAULTNULL,corder_nobigint(20)DEFAULTNULL,cnamevarchar(50)DEFAULTNULL,briefvarchar(50)DEFAULTNULL,pricedoubleDEFAULTNULL,statusint(11)DEFAULTNULL,PRIMARYKEY(cid))ENGINEInnoDBDEFAULTCHARSETutf8分表策略配置 (对id进行哈希取模)#水平分库-分表策略 #----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid ##----分片算法配置---- ##分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nameinline-hash-mod #分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.typeINLINE #分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.props.algorithm-expressiont_course_$-{Math.abs(cid.hashCode()) % 2}完整配置文件# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/course_db0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/course_db1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb$-{0..1}.t_course_$-{0..1} ##2.配置分片策略(分片策略包括分片键和分片算法) #2.1 分片键名称: user_id spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-columnuser_id #2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-nametable-inline #2.3 分片算法类型: 行表达式分片算法(标准分片算法下包含-行表达式分片算法) spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.typeINLINE #2.4 分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expressiondb$-{user_id % 2} #3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.columncid #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-namealg_snowflake #3.3 分布式序列-算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.typeSNOWFLAKE #4水平分库-分表策略 #4.1----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid ##----分片算法配置---- ##4.2分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nameinline-hash-mod #4.3分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.typeINLINE #4.4分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.props.algorithm-expressiont_course_$-{Math.abs(cid.hashCode()) % 2} mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl官方提供分片算法配置https://shardingsphere.apache.org/document/current/cn/dev-manual/sharding/#----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid #----分片算法配置---- #分片算法名称 - 取模分片算法 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nametable-hash-mod #分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.typeHASH_MOD #分片算法属性配置-分片数量,有两个表值设置为2 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count22.3.5.3 水平分库测试测试插入数据//水平分库 -- 分表策略TestpublicvoidtestInsertCourseTable(){for(inti100;i150;i){CoursecoursenewCourse();course.setUserId(1Li);course.setCname(Java面试题详解);course.setCorderNo(1000Li);course.setBrief(经典的10000道面试题);course.setPrice(100.00);course.setStatus(1);courseMapper.insert(course);}}TestpublicvoidtestHashMod(){//cid的hash值为偶数时,插入对应数据库的t_course_0表,为奇数插入对应数据库的t_course_1Longcid1175196313105465345L;//获取到cidinthashcid.hashCode();System.out.println(hash);System.out.println(Math.abs(hash%2));//获取针对cid进行hash取模后的值}两台服务器中的两个表都已经有数据2.3.5.4 水平分库查询下边来测试查询看看shardingjdbc是怎么把多个表的数据汇总查询出来的//查询所有记录TestpublicvoidtestShardingSelectAll(){ListCoursecourseListcourseMapper.selectList(null);courseList.forEach(System.out::println);}查看日志: 查询了两个数据源每个数据源中使用UNION ALL连接两个表//根据user_id进行查询TestpublicvoidtestSelectByUserId(){QueryWrapperCoursecourseQueryWrappernewQueryWrapper();courseQueryWrapper.eq(user_id,2L);ListCoursecoursescourseMapper.selectList(courseQueryWrapper);courses.forEach(System.out::println);}查看日志: 查询了一个数据源使用UNION ALL连接数据源中的两个表2.3.5.5 分片算法HASH_MOD和MODHASH_MOD和MOD是shardingjdbc中自带的分片算法上边水平分库使用的是**t_course_$ -{Math.abs(cid.hashCode()) % 2}**取cid的hash值取模进行分库shardingjdbc有个集成的分片规律HASH_MOD就和t_course_ $-{Math.abs(cid.hashCode()) % 2}分片规律差不多分表的策略db$-{user_id % 2}可以用shardingjdbc中的MOD来替代效果都是一样HASH_MOD配置文件内容#----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid #----分片算法配置---- #分片算法名称 - 取模分片算法 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nametable-hash-mod #分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.typeHASH_MOD #分片算法属性配置-分片数量,有两个表值设置为2 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count2MOD配置文件内容###2.配置分片策略(分片策略包括分片键和分片算法) ##2.1 分片键名称: user_id spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-columnuser_id ##2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-nametable-mod #2.3 --分片算法 spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.typeMOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count2完整配置文件内容# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/course_db0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/course_db1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb$-{0..1}.t_course_$-{0..1} ###2.配置分片策略(分片策略包括分片键和分片算法) ##2.1 分片键名称: user_id spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-columnuser_id ##2.2 分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-nametable-mod #2.3 --分片算法 spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.typeMOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count2 #3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.columncid #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-namealg_snowflake #3.3 分布式序列-算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.typeSNOWFLAKE #----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid #4水平分库-分表策略 #4.1----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nametable-hash-mod ###----分片算法配置---- #4.2分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.typeHASH_MOD #4.3分片算法属性配置-分片数量,有两个表值设置为2 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count2 mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl测试TestpublicvoidtestInsertCourseTable()throwsInterruptedException{for(inti100;i150;i){Thread.sleep(10);CoursecoursenewCourse();course.setUserId(1Li);course.setCname(Java面试题详解);course.setCorderNo(1000Li);course.setBrief(经典的10000道面试题);course.setPrice(100.00);course.setStatus(1);courseMapper.insert(course);}}2.3.5.6 水平分库总结水平分库包含了分库策略和分表策略.分库策略 ,目的是将一个逻辑表 , 映射到多个数据源#水平分库-分库策略 #----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-columnuser_id #----分片算法配置---- #分片算法名称 - 行表达式分片算法 spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.standard.sharding-algorithm-nametable-inline #分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.typeINLINE #分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expressiondb$-{user_id % 2}分表策略, 如何将一个逻辑表 , 映射为多个 实际表#水平分库-分表策略 #----分片列名称---- spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-columncid ##----分片算法配置---- #分片算法名称 spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-nameinline-hash-mod #分片算法类型 spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.typeINLINE #分片算法属性配置 spring.shardingsphere.rules.sharding.sharding-algorithms.inline-hash-mod.props.algorithm-expressiont_course_$-{Math.abs(cid.hashCode()) % 2}2.3.6 实现绑定表先来回顾一下绑定表的概念: 指的是分片规则一致的关系表主表、子表例如t_order和t_order_item均按照order_id分片则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联可以提升关联查询效率。注: 绑定表是建立在多表关联的基础上的.所以我们先来完成多表关联的配置2.3.6.1 数据准备先在两个服务器中分别创建shardingjdbc这个数据库具体库和表如下server01:server02:创建表在server01服务器上的shardingjdbc0数据库 和server02服务器上的shardingjdbc1数据库分别创建t_order和t_order_item表 ,表结构如下:CREATETABLEt_order_0(order_idbigintNOTNULLCOMMENT订单ID,user_idintNOTNULLCOMMENT用户ID,product_namevarchar(255)NOTNULLCOMMENT商品名称,total_pricedecimal(10,2)NOTNULLCOMMENT总价,statusvarchar(50)DEFAULTCREATEDCOMMENT订单状态,create_timedatetimeDEFAULTCURRENT_TIMESTAMP,PRIMARYKEY(order_id));CREATETABLEt_order_1(order_idbigintNOTNULLCOMMENT订单ID,user_idintNOTNULLCOMMENT用户ID,product_namevarchar(255)NOTNULLCOMMENT商品名称,total_pricedecimal(10,2)NOTNULLCOMMENT总价,statusvarchar(50)DEFAULTCREATEDCOMMENT订单状态,create_timedatetimeDEFAULTCURRENT_TIMESTAMP,PRIMARYKEY(order_id));CREATETABLEt_order_item_0(item_idbigintNOTNULLCOMMENT订单项ID,order_idbigintNOTNULLCOMMENT订单ID,product_namevarchar(255)NOTNULLCOMMENT商品名称,pricedecimal(10,2)NOTNULLCOMMENT单价,user_idintNOTNULLCOMMENT用户ID,quantityintNOTNULLCOMMENT数量,total_pricedecimal(10,2)NOTNULLCOMMENT小计,create_timedatetimeDEFAULTCURRENT_TIMESTAMP,PRIMARYKEY(item_id));CREATETABLEt_order_item_1(item_idbigintNOTNULLCOMMENT订单项ID,order_idbigintNOTNULLCOMMENT订单ID,product_namevarchar(255)NOTNULLCOMMENT商品名称,pricedecimal(10,2)NOTNULLCOMMENT单价,user_idintNOTNULLCOMMENT用户ID,quantityintNOTNULLCOMMENT数量,total_pricedecimal(10,2)NOTNULLCOMMENT小计,create_timedatetimeDEFAULTCURRENT_TIMESTAMP,PRIMARYKEY(item_id));2.3.6.2 创建实体类TableName(t_order)DataToStringpublicclassTOrder{TableIdprivateLongorderId;privateIntegeruserId;privateStringproductName;privateBigDecimaltotalPrice;privateStringstatus;privateLocalDateTimecreateTime;}TableName(t_order_item)DataToStringpublicclassTOrderItem{TableIdprivateLongitemId;privateLongorderId;privateStringproductName;privateBigDecimalprice;privateIntegerquantity;privateIntegeruserId;privateBigDecimaltotalPrice;privateLocalDateTimecreateTime;}2.3.6.3 创建mapperMapperpublicinterfaceTOrderMapperextendsBaseMapperTOrder{}MapperpublicinterfaceTOrderItemMapperextendsBaseMapperTOrderItem{}2.3.6.4 配置多表关联t_order的分片表、分片策略、分布式序列策略和t_order_item保持一致数据源# 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456数据节点#1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodesdb$-{0..1}.t_order_$-{0..1} spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodesdb$-{0..1}.t_order_item_$-{0..1}分库策略#2.水平分库-分库策略 ## t_order 分库策略 spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-columnuser_Id spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-nametable-mod # ----t_course_section分库策略 spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-columnuser_Id spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-nametable-mod分表策略#水平分库-分表策略 ## t_order 分表策略 spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-columnorder_Id spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-nametable-hash-mod ## t_order_item 分表策略 spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-columnorder_Id spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-nametable-hash-mod分片算法#3.分片算法 spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.typeMOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count2 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.typeHASH_MOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count2完整配置文件# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #1.配置数据节点 #指定course表的分布情况(配置表在哪个数据库,表名是什么) spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodesdb$-{0..1}.t_order_$-{0..1} spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodesdb$-{0..1}.t_order_item_$-{0..1} #2.水平分库-分库策略 ## t_order 分库策略 spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-columnuser_Id spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-nametable-mod # ----t_course_section分库策略 spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-columnuser_Id spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-nametable-mod #水平分库-分表策略 ## t_order 分表策略 spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-columnorder_Id spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-nametable-hash-mod ## t_order_item 分表策略 spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-columnorder_Id spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-nametable-hash-mod #3.分片算法 spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.typeMOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count2 spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.typeHASH_MOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count2 #3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.columncid #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-namealg_snowflake #3.分布式序列配置 #3.1 分布式序列-列名称 spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.columnitem_id #3.2 分布式序列-算法名称 spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-namealg_snowflake_item #3.3 分布式序列-算法类型 spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.typeSNOWFLAKE mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl spring.shardingsphere.rules.sharding.binding-tables[0]t_order,t_order_item2.3.6.5 测试插入数据TestpublicvoidcreateOrderAndItems(){for(intj0;j10;j){// 1. 创建订单主表记录TOrderordernewTOrder();order.setUserId(1j);order.setProductName(iPhone 15 Pro);order.setTotalPrice(newBigDecimal(8999.00));order.setStatus(CREATED);order.setCreateTime(LocalDateTime.now());// 插入主表orderMapper.insert(order);System.out.println(主单已插入: order);// 2. 创建订单项多个商品for(inti1;i2;i){TOrderItemitemnewTOrderItem();item.setOrderId(order.getOrderId());item.setProductName(配件i);item.setPrice(newBigDecimal(99.00));item.setQuantity(1);item.setUserId(order.getUserId());item.setTotalPrice(newBigDecimal(99.00));item.setCreateTime(LocalDateTime.now());orderItemMapper.insert(item);System.out.println(订单项已插入: item);}}}2.3.6.6 配置绑定表需求说明:查询每个订单的订单号和订单名称和购买数量根据需求编写SQLSELECTt_order.order_Id,t_order.product_name,t_order_item.quantityFROMt_orderINNERjoint_order_itemont_order.order_Idt_order_item.order_Id创建DTO类DatapublicclassTOrderDTO{TableIdprivateLongorderId;privateStringproductName;privateIntegerquantity;}添加Mapper方法MapperpublicinterfaceTOrderMapperextendsBaseMapperTOrder{Select(SELECT t_order.order_Id,t_order.product_name,t_order_item.quantity FROM t_order INNER join t_order_item on t_order.order_Id t_order_item.order_Id )ListTOrderDTOfindItemNamesByOrderId();}进行关联查询TestpublicvoidfindItemNamesByOrderId(){ListTOrderDTOtOrderDTOSorderMapper.findItemNamesByOrderId();tOrderDTOS.forEach(System.out::println);}**如果不配置绑定表测试的结果为8个SQL。**多表关联查询会出现笛卡尔积关联。配置绑定表https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/sharding/#绑定表 spring.shardingsphere.rules.sharding.binding-tables[0]t_course,t_course_section如果配置绑定表测试的结果为4个SQL。多表关联查询不会出现笛卡尔积关联关联查询效率将大大提升。2.3.6.7 总结以order表和order_item表为例它们在每个数据库中都存在多个分片表。如果两者的分片策略完全一致即使用相同的分片键和分片算法必须将它们配置为绑定表Binding Tables。否则在执行多表 JOIN 查询时ShardingSphere-JDBC 无法确定哪些具体的分片表之间存在对应关系只能对所有分片组合进行笛卡尔积式的关联导致查询性能急剧下降甚至引发不必要的全节点扫描。2.3.7 实现广播表(公共表)2.3.7.1 公共表介绍公共表属于系统中数据量较小变动少而且属于高频联合查询的依赖表。参数表、数据字典表等属于此类型。可以将这类表在每个数据库都保存一份所有更新操作都同时发送到所有分库执行。接下来看一下如何使用Sharding-JDBC实现公共表的数据维护。2.3.7.2 代码编写1) 创建表分别在msb_course_db0,msb_course_db1,msb_user_db都创建t_district表-- 区域表CREATETABLEt_district(idBIGINT(20)PRIMARYKEYCOMMENT区域ID,district_nameVARCHAR(100)COMMENT区域名称,LEVELINTCOMMENT等级);2) 创建实体类TableName(t_district)DatapublicclassDistrict{TableId(typeIdType.ASSIGN_ID)privateLongid;privateStringdistrictName;privateintlevel;}3) 创建mapperMapperpublicinterfaceDistrictMapperextendsBaseMapperDistrict{}2.3.7.3 广播表配置数据源# 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印SQl spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.names db0,db1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #数据节点可不配置默认情况下向所有数据源广播 spring.shardingsphere.rules.sharding.tables.t_district.actual-data-nodesdb$-{0..1}.t_district mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl广播表配置#------------------------广播表配置 # 广播表规则列表 spring.shardingsphere.rules.sharding.broadcast-tables[0]t_district2.3.7.4 测试广播表//广播表: 插入数据 两个数据源中都会插入TestpublicvoidtestBroadcast(){DistrictdistrictnewDistrict();district.setDistrictName(昌平区);district.setLevel(1);districtMapper.insert(district);}//查询操作只从一个节点获取数据, 随机负载均衡规则TestpublicvoidtestSelectBroadcast(){ListDistrictdistrictListdistrictMapper.selectList(null);districtList.forEach(System.out::println);}2.3.7.5 总结由于ShardingSphere-JDBC 不支持跨数据库实例即跨数据源的 JOIN 操作所有关联查询必须在同一个数据库节点内完成。当 SQL 中涉及分片表与非分片表如字典表的 JOIN 时若该非分片表未被配置为广播表Broadcast TableShardingSphere 将无法确定其所在的数据节点导致路由失败并抛出异常。因此此类公共表必须显式配置为广播表使其在每个数据库实例中都存在完整副本从而确保 JOIN 查询能在单个节点内正确执行。2.4 读写分离详解与实战2.4.1 读写分离架构介绍2.4.1.1 读写分离原理**读写分离原理**读写分离就是让主库处理事务性操作从库处理select查询。数据库复制被用来把事务性查询导致的数据变更同步到从库同时主库也可以select查询。注意: 读写分离的数据节点中的数据内容是一致。读写分离的基本实现主库负责处理事务性的增删改操作从库负责处理查询操作能够有效的避免由数据更新导致的行锁使得整个系统的查询性能得到极大的改善。读写分离是根据 SQL 语义的分析将读操作和写操作分别路由至主库与从库。通过一主多从的配置方式可以将查询请求均匀的分散到多个数据副本能够进一步的提升系统的处理能力。使用多主多从的方式不但能够提升系统的吞吐量还能够提升系统的可用性可以达到在任何一个数据库宕机甚至磁盘物理损坏的情况下仍然不影响系统的正常运行将用户表的写操作和读操路由到不同的数据库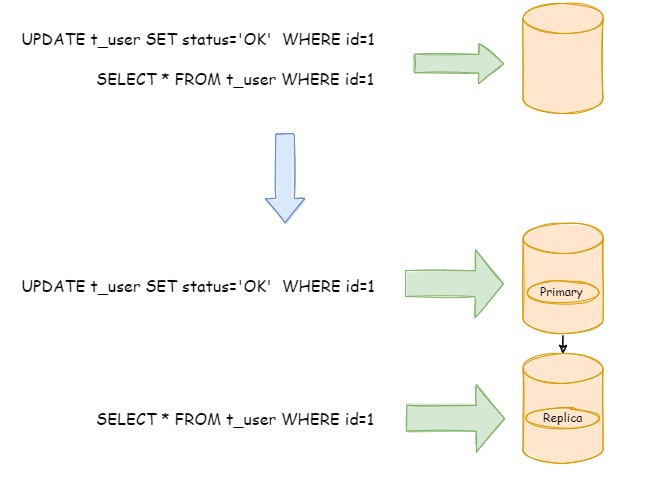2.4.1.2 读写分离应用方案在数据量不是很多的情况下我们可以将数据库进行读写分离以应对高并发的需求通过水平扩展从库来缓解查询的压力。如下分表读写分离在数据量达到500万的时候这时数据量预估千万级别我们可以将数据进行分表存储。分库分表读写分离在数据量继续扩大这时可以考虑分库分表将数据存储在不同数据库的不同表中如下读写分离虽然可以提升系统的吞吐量和可用性但同时也带来了数据不一致的问题包括多个主库之间的数据一致性以及主库与从库之间的数据一致性的问题。 并且读写分离也带来了与数据分片同样的问题它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。透明化读写分离所带来的影响让使用方尽量像使用一个数据库一样使用主从数据库集群是ShardingSphere读写分离模块的主要设计目标。主库、从库、主从同步、负载均衡核心功能提供一主多从的读写分离配置。仅支持单主库可以支持独立使用也可以配合分库分表使用独立使用读写分离支持SQL透传。不需要SQL改写流程同一线程且同一数据库连接内能保证数据一致性。如果有写入操作后续的读操作均从主库读取。基于Hint的强制主库路由。可以强制路由走主库查询实时数据避免主从同步数据延迟。不支持项主库和从库的数据同步主库和从库的数据同步延迟主库双写或多写跨主库和从库之间的事务的数据不一致。建议在主从架构中事务中的读写均用主库操作。2.4.2 CAP 理论2.4.2.1 CAP理论介绍CAP 定理CAP theorem又被称作布鲁尔定理Brewer’s theorem是加州大学伯克利分校的计算机科学家埃里克·布鲁尔Eric Brewer在 2000 年的 ACM PODC 上提出的一个猜想。对于设计分布式系统的架构师来说CAP 是必须掌握的理论。在一个分布式系统中当涉及读写操作时只能保证一致性Consistence、可用性Availability、分区容错性Partition Tolerance三者中的两个另外一个必须被牺牲。C 一致性Consistency等同于所有节点访问同一份最新的数据副本在分布式环境中,数据在多个副本之间能够保持一致的特性,也就是所有的数据节点里面的数据要是一致的A 可用性Availability每次请求都能够获取到非错的响应(不是错误和超时的响应) , 但是不能够保证获取的数据为最新的数据.意思是只要收到用户的请求服务器就必须给出一个成功的回应. 不要求数据是否是最新的.P 分区容错性Partition Tolerance以实际效果而言,分区相当于对通信的时限要求. 系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况 , 必须对当前操作在C和A之间作出选择.更简单的理解就是: 大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区partition。分区容错的意思是区间通信可能失败可能是丢包也可能是连接中断还可能是拥塞) 但是系统能够继续“履行职责” 正常运行.一般来说分布式系统分区容错无法避免因此可以认为 CAP 的 P 总是成立。根据CAP 定理剩下的 C 和 A 无法同时做到。2.4.2.2 CAP理论特点CAP如何取舍CAP理论的C也就是一致性,不等于事务ACID中的C(数据的一致性), CAP理论中的C可以理解为副本的一致性.即所有的副本的结果都是有一致的.在没有网络分区的单机系统中可以选择保证CA, 但是在分布式系统中存在网络通信环节,网络通信在多机中是不可靠的,P是必须要选择的,为了 保证P就需要在C和A之间作出选择假设有三个副本,写入时有下面两个方案方案一: W1, 一写,向三个副本写入,只要一个副本写入成功,即认为成功一写的情况下,只要写入一个副本成功即可返回写入成功,出现网络分区后,三台机器的数据就有可能出现不一致, 无法保证C. (比如server1与其他节点的网络中断了,那S1与S2 S3 就不一致的了), 但是因为可以正常返回写入成功,A依旧可以保证.方案二: W2, 三写,向三个副本写入,三个副本写入成功,才认为是成功在三写的情况下,要三个副本都写入成功,才可以返回成功,出现网络分区后,无法实现这一点,最终会返回报错,所以没有保证A,但是保证了C.2.4.2.3 分布式数据库对于CAP理论的实践从上面的分析我们可以总结出来: 在分布式环境中,P是一定存在的,一旦出现了网络分区,那么一致性和可用性就一定要抛弃一个.对于NoSQL数据库,更加注重可用性,所以会是一个AP系统.对于分布式关系型数据库,必须要保证一致性,所以会是一个CP系统.分布式关系型数据库仍有高可用性需求,虽然达不到CAP理论中的100%可用性,单一般都具备五个9(99.999%) 以上的高可用.**计算公式: A表示可用性; MTBF表示平均故障间隔; MTTR表示平均恢复时间 **高可用有一个标准,9越多代表越容错, 可用性越高.假设系统一直能够提供服务我们说系统的可用性是100%。如果系统每运行100个时间单位会有1个时间单位无法提供服务我们说系统的可用性是99%。很多公司的高可用目标是4个9也就是99.99%我们可以将分布式关系型数据库看做是CPHA的系统.由此也产生了两个广泛的应用指标.**RPO(Recovery PointObjective): ** 恢复点目标,指数据库在灾难发生后会丢失多长时间的数据.分布式关系型数据库RPO0.RTO(Recovery Time Objective):恢复时间目标,指数据库在灾难发生后到整个系统恢复正常所需要的时间.分布式关系型数据库RTO 几分钟(因为有主备切换,所以一般恢复时间就是几分钟).总结一下: CAP理论并不是让我们选择C或者选择A就完全抛弃另外一个, 这样极端显然是不对的,实际上在设计一个分布式系统时,P是必须的所以要在AC中取舍一个降级。根据不同场景来取舍A或者C.2.4.3 MySQL主从同步2.4.3.1 主从同步原理读写分离是建立在MySQL主从复制基础之上实现的所以必须先搭建MySQL的主从复制架构。主从复制的用途实时灾备用于故障切换读写分离提供查询服务备份避免影响业务主从部署必要条件主库开启binlog日志设置log-bin参数主从server-id不同从库服务器能连通主库主从复制的原理Mysql 中有一种日志叫做 binlog日志二进制日志。这个日志会记录下所有修改了数据库的SQL 语句insert,update,delete,create/alter/drop table, grant 等等。主从复制的原理其实就是把主服务器上的 binlog日志复制到从服务器上执行一遍这样从服务器上的数据就和主服务器上的数据相同了。主库db的更新事件(update、insert、delete)被写到binlog主库创建一个binlog dump thread把binlog的内容发送到从库从库启动并发起连接连接到主库从库启动之后创建一个I/O线程读取主库传过来的binlog内容并写入到relay log从库启动之后创建一个SQL线程从relay log里面读取内容执行读取到的更新事件将更新内容写入到slave的db2.4.3.2 一主一从架构搭建Mysql的主从复制至少是需要两个Mysql的服务当然Mysql的服务是可以分布在不同的服务器上也可以在一台服务器上启动多个服务。准备主机角色用户名密码192.168.116.129masterroot123456192.168.116.128slaveroot123456第一步 master中和slave创建数据库-- 创建数据库CREATEDATABASEitcast;主库中配置① 修改配置文件 /etc/my.cnf#mysql 服务ID保证整个集群环境中唯一取值范围1 – 232-1默认为1 server-id1 #是否只读,1 代表只读, 0 代表读写 read-only0 #指定同步的数据库 binlog-do-dbitcast② 重启MySQL服务器systemctl restart mysqld③ 登录mysql创建远程连接的账号并授予主从复制权限#创建itcast用户并设置密码该用户可在任意主机连接该MySQL服务create useritcast%IDENTIFIED WITH mysql_native_password BYItcast123456;#为 itcast% 用户分配主从复制权限GRANT REPLICATION SLAVE ON *.* TOitcast%;④ 通过指令查看二进制日志坐标showmasterstatus;字段含义说明file : 从哪个日志文件开始推送日志文件position 从哪个位置开始推送日志binlog_ignore_db : 指定不需要同步的数据库从库配置① 修改配置文件 /etc/my.cnf#mysql 服务ID保证整个集群环境中唯一取值范围1 – 2^32-1和主库不一样即可server-id2#是否只读,1 代表只读, 0 代表读写read-only1② 重新启动MySQL服务systemctl restart mysqld③ 登录mysql设置主库配置SOURCE_LOG_FILE和SOURCE_LOG_POS设置的是主库中刚才查询出来的CHANGEREPLICATIONSOURCETOSOURCE_HOST192.168.116.129,SOURCE_USERitcast,SOURCE_PASSWORDItcast123456,SOURCE_LOG_FILEbinlog.000014,SOURCE_LOG_POS479;上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本执行如下SQLCHANGE MASTERTOMASTER_HOST192.168.116.129,MASTER_USERitcast,MASTER_PASSWORDItcast123456,MASTER_LOG_FILEbinlog.000014,MASTER_LOG_POS479;参数名含义8.0.23之前SOURCE_HOST主库IP地址MASTER_HOSTSOURCE_USER连接主库的用户名MASTER_USERSOURCE_PASSWORD连接主库的密码MASTER_PASSWORDSOURCE_LOG_FILEbinlog日志文件名MASTER_LOG_FILESOURCE_LOG_POSbinlog日志文件位置MASTER_LOG_POS④ 开启同步操作startreplica;#8.0.22之后startslave;#8.0.22之前⑤ 查看主从同步状态showreplicastatus;#8.0.22之后showslavestatus;#8.0.22之前Replica_IO_Running: Yes和Replica_SQL_Running: Yes说明配置成功测试在主库中itcast数据库中执行如下-- 创建表CREATETABLEusers(idINT(11)PRIMARYKEYAUTO_INCREMENT,NAMEVARCHAR(20)DEFAULTNULL,ageINT(11)DEFAULTNULL);-- 插入数据INSERTINTOusersVALUES(NULL,user1,20);INSERTINTOusersVALUES(NULL,user2,21);INSERTINTOusersVALUES(NULL,user3,22);查看从库是否已经将users表和数据同步过来2.4.4 Sharding-JDBC实现读写分离Sharding-JDBC读写分离则是根据SQL语义的分析将读操作和写操作分别路由至主库与从库。它提供透明化读写分离让使用方尽量像使用一个数据库一样使用主从数据库集群。2.4.4.1 数据准备为了实现Sharding-JDBC的读写分离首先要进行mysql的主从同步配置。在上面的课程中我们已经配置完成了.在主服务器中的 itcast数据库 创建商品表CREATETABLEproducts(pidbigint(32)NOTNULLAUTO_INCREMENT,pnamevarchar(50)DEFAULTNULL,priceint(11)DEFAULTNULL,flagvarchar(2)DEFAULTNULL,PRIMARYKEY(pid))ENGINEInnoDBDEFAULTCHARSETutf8主库新建表之后,从库会根据binlog日志,同步创建.主库从库2.4.4.2 环境准备1) 创建实体类TableName(products)DatapublicclassProducts{TableId(valuepid,typeIdType.AUTO)privateLongpid;privateStringpname;privateintprice;privateStringflag;}2) 创建MapperMapperpublicinterfaceProductsMapperextendsBaseMapperProducts{}2.4.4.3 配置读写分离https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting/application.properties# 应用名称 spring.application.nameshardingjdbc-table-write-read #数据源配置 # 配置真实数据源 spring.shardingsphere.datasource.namesmaster,slave #数据源1 spring.shardingsphere.datasource.slave.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.slave.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave.url jdbc:mysql://192.168.116.128:3306/itcast?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.slave.username root spring.shardingsphere.datasource.slave.password 123456 #数据源2 spring.shardingsphere.datasource.master.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.master.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.master.url jdbc:mysql://192.168.116.129:3306/itcast?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.master.username root spring.shardingsphere.datasource.master.password 123456 # 读写分离类型如: StaticDynamic, ms1 包含了 m1 和 s1 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms1.typeStatic # 写数据源名称 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms1.props.write-data-source-namemaster # 读数据源名称多个从数据源用逗号分隔 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms1.props.read-data-source-namesslave # 打印SQl spring.shardingsphere.props.sql-showtrue负载均衡相关配置2.4.4.4 读写分离测试//插入测试TestpublicvoidtestInsertProducts(){ProductsproductsnewProducts();products.setPname(电视机);products.setPrice(100);products.setFlag(0);productsMapper.insert(products);}TestpublicvoidtestSelectProducts(){QueryWrapperProductsqueryWrappernewQueryWrapper();queryWrapper.eq(pname,电视机);ListProductsproductsproductsMapper.selectList(queryWrapper);products.forEach(System.out::println);}2.4.4.5 事务读写分离测试为了保证主从库间的事务一致性避免跨服务的分布式事务ShardingSphere-JDBC的主从模型中事务中的数据读写均用主库。不添加Transactionalinsert对主库操作select对从库操作添加Transactional则insert和select均对主库操作**注意**在JUnit环境下的Transactional注解默认情况下就会对事务进行回滚即使在没加注解Rollback也会对事务回滚//事务测试Transactional//开启事务TestpublicvoidtestTrans(){ProductsproductsnewProducts();products.setPname(洗碗机);products.setPrice(2000);products.setFlag(1);productsMapper.insert(products);QueryWrapperProductsqueryWrappernewQueryWrapper();queryWrapper.eq(pname,洗碗机);ListProductslistproductsMapper.selectList(queryWrapper);list.forEach(System.out::println);}2.4.5 负载均衡算法2.4.5.1 一主两从架构上边再搭建一主一从时用到过129和128两个服务器再操作之前先还原两个服务器的主从架构分别在两个服务器上执行下边的sqlSTOP SLAVE;RESET SLAVEALL;准备主机角色用户名密码192.168.116.129masterroot123456192.168.116.128slaveroot123456192.168.116.130slaveroot123456第一步 master中和slave创建数据库-- 创建数据库CREATEDATABASEitcast;主库中配置① 修改配置文件 /etc/my.cnf#mysql 服务ID保证整个集群环境中唯一取值范围1 – 232-1默认为1 server-id1 #是否只读,1 代表只读, 0 代表读写 read-only0 #指定同步的数据库 binlog-do-dbitcast② 重启MySQL服务器systemctl restart mysqld③ 登录mysql创建远程连接的账号并授予主从复制权限#创建itcast用户并设置密码该用户可在任意主机连接该MySQL服务create useritcast%IDENTIFIED WITH mysql_native_password BYItcast123456;#为 itcast% 用户分配主从复制权限GRANT REPLICATION SLAVE ON *.* TOitcast%;④ 通过指令查看二进制日志坐标showmasterstatus;字段含义说明file : 从哪个日志文件开始推送日志文件position 从哪个位置开始推送日志binlog_ignore_db : 指定不需要同步的数据库从库192.168.116.128配置① 修改配置文件 /etc/my.cnf#mysql 服务ID保证整个集群环境中唯一取值范围1 – 2^32-1和主库不一样即可server-id2#是否只读,1 代表只读, 0 代表读写read-only1② 重新启动MySQL服务systemctl restart mysqld③ 登录mysql设置主库配置SOURCE_LOG_FILE和SOURCE_LOG_POS设置的是主库中刚才查询出来的CHANGEREPLICATIONSOURCETOSOURCE_HOST192.168.116.129,SOURCE_USERitcast,SOURCE_PASSWORDItcast123456,SOURCE_LOG_FILEbinlog.000031,SOURCE_LOG_POS156;上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本执行如下SQLCHANGE MASTERTOMASTER_HOST192.168.116.129,MASTER_USERitcast,MASTER_PASSWORDItcast123456,MASTER_LOG_FILEbinlog.000031,MASTER_LOG_POS156;参数名含义8.0.23之前SOURCE_HOST主库IP地址MASTER_HOSTSOURCE_USER连接主库的用户名MASTER_USERSOURCE_PASSWORD连接主库的密码MASTER_PASSWORDSOURCE_LOG_FILEbinlog日志文件名MASTER_LOG_FILESOURCE_LOG_POSbinlog日志文件位置MASTER_LOG_POS④ 开启同步操作startreplica;#8.0.22之后startslave;#8.0.22之前⑤ 查看主从同步状态showreplicastatus;#8.0.22之后showslavestatus;#8.0.22之前Replica_IO_Running: Yes和Replica_SQL_Running: Yes说明配置成功从库192.168.116.130配置① 修改配置文件 /etc/my.cnf#mysql 服务ID保证整个集群环境中唯一取值范围1 – 2^32-1和主库不一样即可server-id3#是否只读,1 代表只读, 0 代表读写read-only1② 重新启动MySQL服务systemctl restart mysqld③ 登录mysql设置主库配置SOURCE_LOG_FILE和SOURCE_LOG_POS设置的是主库中刚才查询出来的CHANGEREPLICATIONSOURCETOSOURCE_HOST192.168.116.129,SOURCE_USERitcast,SOURCE_PASSWORDItcast123456,SOURCE_LOG_FILEbinlog.000031,SOURCE_LOG_POS156;上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本执行如下SQLCHANGE MASTERTOMASTER_HOST192.168.116.129,MASTER_USERitcast,MASTER_PASSWORDItcast123456,MASTER_LOG_FILEbinlog.000031,MASTER_LOG_POS156;参数名含义8.0.23之前SOURCE_HOST主库IP地址MASTER_HOSTSOURCE_USER连接主库的用户名MASTER_USERSOURCE_PASSWORD连接主库的密码MASTER_PASSWORDSOURCE_LOG_FILEbinlog日志文件名MASTER_LOG_FILESOURCE_LOG_POSbinlog日志文件位置MASTER_LOG_POS④ 开启同步操作startreplica;#8.0.22之后startslave;#8.0.22之前⑤ 查看主从同步状态showreplicastatus;#8.0.22之后showslavestatus;#8.0.22之前Replica_IO_Running: Yes和Replica_SQL_Running: Yes说明配置成功测试在主库中执行如下dropdatabaseifexistsitcast;createdatabaseitcast;useitcast;-- 创建表CREATETABLEproducts(pidbigint(32)NOTNULLAUTO_INCREMENT,pnamevarchar(50)DEFAULTNULL,priceint(11)DEFAULTNULL,flagvarchar(2)DEFAULTNULL,PRIMARYKEY(pid))ENGINEInnoDBDEFAULTCHARSETutf8insertintoproductsvalues(1,拖鞋,20,1);insertintoproductsvalues(2,拖鞋,20,1);insertintoproductsvalues(3,拖鞋,20,1);查看从库是否已经将products表同步过来2.4.5.2 负载均衡测试负载均衡算法就是用在如果有多个从库的时候决定查询哪个从库的数据一共有如下的算法**轮询算法ROUND_ROBIN**原理按照配置的数据源列表顺序依次轮流地将请求分发到每一个可用的数据源上例如有 2个读库read_ds_0、read_ds_1则请求的分发顺序为请求1 → read_ds_0 请求2 → read_ds_1 请求3 → read_ds_0 请求4 → read_ds_1随机访问算法RANDOM每次请求时从所有可用的读数据源中随机选择一个进行访问权重访问算法WEIGHT为每个数据源配置一个权重值如read_ds_03,read_ds_11。使用加权随机算法如轮盘赌算法权重越高的数据源被选中的概率越大。例如read_ds_0被选中的概率是 75%read_ds_1是 25%测试WEIGHT算法配置文件如下# 应用名称 spring.application.nameshardingjdbc-table-write-read #数据源配置 # 配置真实数据源 spring.shardingsphere.datasource.namesmaster,slave #数据源1 spring.shardingsphere.datasource.master.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.master.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.master.url jdbc:mysql://192.168.116.128:3306/itcast?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.master.username root spring.shardingsphere.datasource.master.password 123456 #数据源2 spring.shardingsphere.datasource.slave1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.slave1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave1.url jdbc:mysql://192.168.116.129:3306/itcast?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.slave1.username root spring.shardingsphere.datasource.slave1.password 123456 #数据源3 spring.shardingsphere.datasource.slave2.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.slave2.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave2.url jdbc:mysql://192.168.116.130:3306/itcast?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.slave2.username root spring.shardingsphere.datasource.slave2.password 123456 # 打印SQl spring.shardingsphere.props.sql-showtrue # 读写分离类型如: StaticDynamic, ms2 包含了 m1 和 s1 s2 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.typestatic # 写数据源名称 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.props.write-data-source-namemaster # 读数据源名称多个从数据源用逗号分隔 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.props.read-data-source-namesslave1,slave2 # 负载均衡算法名称 spring.shardingsphere.rules.readwrite-splitting.data-sources.ms2.load-balancer-namealg_weight # 负载均衡算法配置 # 负载均衡算法类型 spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.typeWEIGHT spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave11 spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave23TestpublicvoidtestSelectProducts2(){for(inti0;i12;i){ListProductsproductsproductsMapper.selectList(null);}}查询结果中有8次从slave2查询4次从slave1查询RANDOM和ROUND_ROBIN配置方式如下2.5 强制路由详解与实战2.5.1 强制路由介绍https://shardingsphere.apache.org/document/4.1.0/cn/manual/sharding-jdbc/usage/hint/在一些应用场景中分片条件并不存在于SQL而存在于外部业务逻辑。因此需要提供一种通过在外部业务代码中指定路由配置的一种方式在ShardingSphere中叫做Hint。如果使用Hint指定了强制分片路由那么SQL将会无视原有的分片逻辑直接路由至指定的数据节点操作。Hint使用场景数据分片操作如果分片键没有在SQL或数据表中而是在业务逻辑代码中读写分离操作如果强制在主库进行某些数据操作2.5.2 强制路由的使用基于 Hint 进行强制路由的设计和开发过程需要遵循一定的约定同时ShardingSphere 也提供了专门的 HintManager 来简化强制路由的开发过程.2.5.2.1 环境准备在shardingjdbc0和shardingjdbc1中创建 t_course表.CREATETABLEt_course(cidbigint(20)NOTNULL,user_idbigint(20)DEFAULTNULL,corder_nobigint(20)DEFAULTNULL,cnamevarchar(50)DEFAULTNULL,briefvarchar(50)DEFAULTNULL,pricedoubleDEFAULTNULL,statusint(11)DEFAULTNULL,PRIMARYKEY(cid))ENGINEInnoDBDEFAULTCHARSETutf82.5.2.2 代码编写TableName(t_course)DataToStringpublicclassCourseimplementsSerializable{TableId(typeIdType.ASSIGN_ID)privateLongcid;privateLonguserId;privateLongcorderNo;privateStringcname;privateStringbrief;privatedoubleprice;privateintstatus;}CourseMapperRepositorypublicinterfaceCourseMapperextendsBaseMapperCourse{}自定义MyHintShardingAlgorithm类在该类中编写分库或分表路由策略实现HintShardingAlgorithm接口,重写doSharding方法// 泛型Long表示传入的参数是Long类型publicclassMyHintShardingAlgorithmimplementsHintShardingAlgorithmLong{publicMyHintShardingAlgorithm(){System.out.println(MyHintShardingAlgorithm 被创建了);}OverridepublicCollectionStringdoSharding(CollectionStringavailableTargetNames,HintShardingValueLongshardingValue){CollectionStringresultnewArrayList();for(Stringtarget:availableTargetNames){for(Longvalue:shardingValue.getValues()){if(target.endsWith(String.valueOf(value%2))){result.add(target);}}}returnresult;}Overridepublicvoidinit(){}OverridepublicStringgetType(){// CLASS_BASED 模式下不会用到此 type但实现返回值无妨returnMY_HINT;}}参数解析参数含义availableTargetNames当前所有可用的数据节点名称例如[db0, db1]和[t_course_0, t_course_1]shardingValue通过hintManager.addDatabaseShardingValue(...)或addTableShardingValue(...)传入的值Collection实际要路由到的目标2.5.2.3 配置文件application.properties# 启用 debug 日志 logging.level.org.apache.shardingsphereDEBUG # 应用名称 spring.application.nameshardingsphere-jdbc-table # 打印 SQL spring.shardingsphere.props.sql-showtrue # 定义多个数据源 spring.shardingsphere.datasource.namesdb0,db1 # 数据源1 spring.shardingsphere.datasource.db0.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-namecom.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.db0.jdbc-urljdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalseserverTimezoneAsia/Shanghai spring.shardingsphere.datasource.db0.usernameroot spring.shardingsphere.datasource.db0.password123456 # 数据源2 spring.shardingsphere.datasource.db1.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-namecom.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.db1.jdbc-urljdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalseserverTimezoneAsia/Shanghai spring.shardingsphere.datasource.db1.usernameroot spring.shardingsphere.datasource.db1.password123456 # 默认数据源建议保留 spring.shardingsphere.rules.sharding.default-data-source-namedb0 # t_course 表实际数据节点 spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodesdb${0..1}.t_course_${0..1} # 数据库分片策略 - Hint spring.shardingsphere.rules.sharding.tables.t_course.database-strategy.hint.sharding-algorithm-namemyHint # 表分片策略 - Hint spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.hint.sharding-algorithm-namemyHint # 分片算法定义 - MY_HINT spring.shardingsphere.rules.sharding.sharding-algorithms.myHint.typeCLASS_BASED spring.shardingsphere.rules.sharding.sharding-algorithms.myHint.props.strategyHINT spring.shardingsphere.rules.sharding.sharding-algorithms.myHint.props.algorithmClassNamecom.zhp.hint.MyHintShardingAlgorithm2.5.2.4 强制路由到库到表测试通过设置addDatabaseShardingValue决定路由到哪个数据库addTableShardingValue决定路由到哪张表TestpublicvoidtestHintInsert(){HintManagerhintManagerHintManager.getInstance();hintManager.addDatabaseShardingValue(db,1L);hintManager.addTableShardingValue(t_course,0L);for(inti1;i9;i){CoursecoursenewCourse();course.setCid(Long.parseLong(String.valueOf(i)));course.setUserId(1001Li);course.setCname(Java经典面试题讲解);course.setBrief(课程涵盖目前最容易被问到的10000道Java面试题);course.setPrice(100.0);course.setStatus(1);courseMapper.insert(course);}}2.5.2.5 强制路由到库到表查询测试//测试查询TestpublicvoidtestHintSelectTable(){HintManagerhintManagerHintManager.getInstance();//强制路由到db1数据库hintManager.addDatabaseShardingValue(db,1L);//强制路由到t_course_1表hintManager.addTableShardingValue(t_course,0L);ListCoursecoursescourseMapper.selectList(null);courses.forEach(System.out::println);}2.5.2.6 强制路由走主库查询测试在读写分离结构中为了避免主从同步数据延迟及时获取刚添加或更新的数据可以采用强制路由走主库查询实时数据使用hintManager.setMasterRouteOnly设置主库路由即可。配置文件# 应用名称spring.application.namesharding-jdbc-hint01# 定义多个数据源spring.shardingsphere.datasource.namesm1,s1#数据源1spring.shardingsphere.datasource.db0.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-namecom.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.urljdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalsespring.shardingsphere.datasource.db0.usernameroot spring.shardingsphere.datasource.db0.password123456#数据源2spring.shardingsphere.datasource.db1.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-namecom.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.urljdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalsespring.shardingsphere.datasource.db1.usernameroot spring.shardingsphere.datasource.db1.password123456#主库与从库的信息spring.shardingsphere.sharding.master-slave-rules.ms1.master-data-source-namem1 spring.shardingsphere.sharding.master-slave-rules.ms1.slave-data-source-namess1#配置数据节点spring.shardingsphere.sharding.tables.products.actual-data-nodesms1.products# 打印SQlspring.shardingsphere.props.sql-showtrue测试//强制路由走主库TestpublicvoidtestHintReadTableToMaster(){HintManagerhintManagerHintManager.getInstance();hintManager.setMasterRouteOnly();ListProductsproductsproductsMapper.selectList(null);products.forEach(System.out::println);}2.5.2.7 SQL执行流程剖析ShardingSphere 3个产品的数据分片功能主要流程是完全一致的如下图所示。SQL解析SQL解析分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解并最终提炼出解析上下文。 Sharding-JDBC采用不同的解析器对SQL进行解析解析器类型如下MySQL解析器Oracle解析器SQLServer解析器PostgreSQL解析器默认SQL解析器查询优化负责合并和优化分片条件如OR等。SQL路由根据解析上下文匹配用户配置的分片策略并生成路由路径。目前支持分片路由和广播路由。SQL改写将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。SQL执行通过多线程执行器异步执行SQL。结果归并将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。2.6 数据加密详解与实战2.6.1 数据加密介绍数据加密(数据脱敏) 是指对某些敏感信息通过脱敏规则进行数据的变形实现敏感隐私数据的可靠保护。涉及客户安全数据或者一些商业性敏感数据如身份证号、手机号、卡号、客户号等个人信息按照规定都需要进行数据脱敏。数据加密模块属于ShardingSphere分布式治理这一核心功能下的子功能模块。Apache ShardingSphere 通过对用户输入的 SQL 进行解析并依据用户提供的加密规则对 SQL 进行改写从而实现对原文数据进行加密并将原文数据可选及密文数据同时存储到底层数据库。在用户查询数据时它仅从数据库中取出密文数据并对其解密最终将解密后的原始数据返回给用户。Apache ShardingSphere自动化透明化了数据脱敏过程让用户无需关注数据脱敏的实现细节像使用普通数据那样使用脱敏数据。2.6.2 整体架构ShardingSphere提供的Encrypt-JDBC和业务代码部署在一起。业务方需面向Encrypt-JDBC进行JDBC编程。加密模块将用户发起的 SQL 进行拦截并通过 SQL 语法解析器进行解析、理解 SQL 行为再依据用户传入的加密规则找出需要加密的字段和所使用的加解密算法对目标字段进行加解密处理后再与底层数据库进行交互。Apache ShardingSphere 会将用户请求的明文进行加密后存储到底层数据库并在用户查询时将密文从数据库中取出进行解密后返回给终端用户。通过屏蔽对数据的加密处理使用户无需感知解析 SQL、数据加密、数据解密的处理过程就像在使用普通数据一样使用加密数据。2.6.3 加密规则脱敏配置主要分为四部分数据源配置加密器配置脱敏表配置以及查询属性配置其详情如下图所示数据源配置指DataSource的配置信息加密器配置指使用什么加密策略进行加解密。目前ShardingSphere内置了两种加解密策略AES/MD5脱敏表配置指定哪个列用于存储密文数据cipherColumn、哪个列用于存储明文数据plainColumn以及用户想使用哪个列进行SQL编写logicColumn查询属性的配置当底层数据库表里同时存储了明文数据、密文数据后该属性开关用于决定是直接查询数据库表里的明文数据进行返回还是查询密文数据通过Encrypt-JDBC解密后返回。2.6.4 脱敏处理流程下图可以看出ShardingSphere将逻辑列与明文列和密文列进行了列名映射。下方图片展示了使用Encrypt-JDBC进行增删改查时其中的处理流程和转换逻辑如下图所示。2.6.5 数据加密实战2.6.5.1 环境搭建创建数据库及表CREATETABLEt_Account(user_idbigint(11)NOTNULL,user_namevarchar(255)DEFAULTNULL,passwordvarchar(255)DEFAULTNULLCOMMENT密码明文,password_encryptvarchar(255)DEFAULTNULLCOMMENT密码密文,password_assistedvarchar(255)DEFAULTNULLCOMMENT辅助查询列,PRIMARYKEY(user_id))ENGINEInnoDBDEFAULTCHARSETutf8创建实体类TableName(t_Account)DatapublicclassAccount{TableId(valueuser_id,typeIdType.ASSIGN_ID)privateLonguserId;privateStringuserName;privateStringpassword;privateStringpasswordEncrypt;privateStringpasswordAssisted;}创建MapperRepositorypublicinterfaceAccountMapperextendsBaseMapperUser{Insert(insert into t_user(user_id,user_name,password) values(#{userId},#{userName},#{password}))voidinsetUser(Userusers);Select(select * from t_user where user_name#{userName} and password#{password})Results({Result(columnuser_id,propertyuserId),Result(columnuser_name,propertyuserName),Result(columnpassword,propertypassword),Result(columnpassword_assisted,propertypasswordAssisted)})ListAccountgetUserInfo(Param(userName)StringuserName,Param(password)Stringpassword);}配置文件# 启用 debug 日志 logging.level.org.apache.shardingsphereDEBUG # 应用名称 spring.application.nameshardingsphere-jdbc-encryption # 打印 SQL spring.shardingsphere.props.sql-showtrue # 定义数据源 spring.shardingsphere.datasource.namesdb0 # 数据源1 spring.shardingsphere.datasource.db0.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-namecom.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.db0.jdbc-urljdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalseserverTimezoneAsia/Shanghai spring.shardingsphere.datasource.db0.usernameroot spring.shardingsphere.datasource.db0.password123456测试插入与查询packagecom.zhp;importcom.baomidou.mybatisplus.core.conditions.query.QueryWrapper;importcom.zhp.entity.*;importcom.zhp.mapper.*;importcom.zhp.utils.SnowFlakeUtil;importorg.apache.shardingsphere.infra.hint.HintManager;importorg.junit.jupiter.api.Test;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.test.context.SpringBootTest;importorg.springframework.transaction.annotation.Transactional;importjava.math.BigDecimal;importjava.time.LocalDateTime;importjava.util.List;SpringBootTestclassShardingsphereJdbcTableApplicationTests{AutowiredprivateAccountMapperaccountMapper;TestpublicvoidtestInsertAccount(){AccountaccountnewAccount();account.setUserName(user2022);account.setPassword(123456);accountMapper.insetUser(account);}TestpublicvoidtestSelectAccount(){ListAccountaccountListaccountMapper.getUserInfo(user2022,123456);accountList.forEach(System.out::println);}}2.6.5.2 加密策略解析https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/encrypt/ShardingSphere提供了两种加密策略用于数据脱敏该两种策略分别对应ShardingSphere的两种加解密的接口即Encryptor和QueryAssistedEncryptor。Encryptor: 该解决方案通过提供encrypt(), decrypt()两种方法对需要脱敏的数据进行加解密。在用户进行INSERT, DELETE, UPDATE时ShardingSphere会按照用户配置对SQL进行解析、改写、路由并会调用encrypt()将数据加密后存储到数据库, 而在SELECT时则调用decrypt()方法将从数据库中取出的脱敏数据进行逆向解密最终将原始数据返回给用户。当前ShardingSphere针对这种类型的脱敏解决方案提供了两种具体实现类分别是MD5(不可逆)AES(可逆)用户只需配置即可使用这两种内置的方案。QueryAssistedEncryptor: 相比较于第一种脱敏方案该方案更为安全和复杂。它的理念是即使是相同的数据如两个用户的密码相同它们在数据库里存储的脱敏数据也应当是不一样的。这种理念更有利于保护用户信息防止撞库成功。当前ShardingSphere针对这种类型的脱敏解决方案并没有提供具体实现类却将该理念抽象成接口提供给用户自行实现。ShardingSphere将调用用户提供的该方案的具体实现类进行数据脱敏。2.6.5.3 默认AES加密算法实现数据加密默认算法支持 AES 和 MD5 两种AES 对称加密: 同一个密钥可以同时用作信息的加密和解密这种加密方法称为对称加密加密明文 密钥 - 密文 解密密文 密钥 - 明文MD5算是一个生成签名的算法,引起结果不可逆.MD5的优点计算速度快加密速度快不需要密钥MD5的缺点: 将用户的密码直接MD5后存储在数据库中是不安全的。很多人使用的密码是常见的组合威胁者将这些密码的常见组合进行单向哈希得到一个摘要组合然后与数据库中的摘要进行比对即可获得对应的密码。https://www.tool.cab/decrypt/md5.html配置文件注意shardingJdbc每个版本的配置文件配置方式变动很大如果使用和本教程使用的shardingjdbc版本不一样自己去shardingjdbc官网找对应版本配置文件配置方式思想都是一样的。# 启用 debug 日志 logging.level.org.apache.shardingsphereDEBUG # 应用名称 spring.application.nameshardingsphere-jdbc-encryption # 打印 SQL spring.shardingsphere.props.sql-showtrue # 定义数据源 spring.shardingsphere.datasource.namesdb0 # 数据源1 spring.shardingsphere.datasource.db0.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-namecom.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.db0.jdbc-urljdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalseserverTimezoneAsia/Shanghai spring.shardingsphere.datasource.db0.usernameroot spring.shardingsphere.datasource.db0.password123456 # 采用AES对称加密策略 spring.shardingsphere.rules.encrypt.encryptors.encryptor_aes.typeaes # ASE算法的密钥 spring.shardingsphere.rules.encrypt.encryptors.encryptor_aes.props.aes-key-value123456abc # password为逻辑列password.plainColumn为数据表明文列password.cipherColumn为数据表密文列 spring.shardingsphere.rules.encrypt.tables.t_Account.columns.password.plain-columnpassword spring.shardingsphere.rules.encrypt.tables.t_Account.columns.password.cipher-columnpassword_encrypt spring.shardingsphere.rules.encrypt.tables.t_Account.columns.password.encryptor-nameencryptor_aes # 查询是否使用密文列 spring.shardingsphere.rules.encrypt.query-with-cipher-columntrue # 打印SQl spring.shardingsphere.props.sql.showtrue测试插入数据TestpublicvoidtestInsertAccount(){AccountaccountnewAccount();account.setUserName(user2022);account.setPassword(123456);accountMapper.insetUser(account);}设置了明文列和密文列运行成功新增时逻辑列会改写成明文列和密文列仅设置明文列运行直接报错所以必须设置加密列仅设置密文列运行成功明文会进行加密数据库实际插入到密文列设置了明文列和密文列spring.shardingsphere.rules.encrypt.query-with-cipher-column为true时查询通过密文列查询返回数据为明文.设置了明文列和密文列spring.shardingsphere.rules.encrypt.query-with-cipher-column为false时查询通过明文列执行返回数据为明文列.2.6.5.4 MD5加密算法实现配置文件# 启用 debug 日志 logging.level.org.apache.shardingsphereDEBUG # 应用名称 spring.application.nameshardingsphere-jdbc-encryption # 打印 SQL spring.shardingsphere.props.sql-showtrue # 定义数据源 spring.shardingsphere.datasource.namesdb0 # 数据源1 spring.shardingsphere.datasource.db0.typecom.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-namecom.mysql.cj.jdbc.Driver spring.shardingsphere.datasource.db0.jdbc-urljdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalseserverTimezoneAsia/Shanghai spring.shardingsphere.datasource.db0.usernameroot spring.shardingsphere.datasource.db0.password123456 # 采用md5 spring.shardingsphere.rules.encrypt.encryptors.encryptor_md5.typeMD5 # password为逻辑列password.plainColumn为数据表明文列password.cipherColumn为数据表密文列 spring.shardingsphere.rules.encrypt.tables.t_Account.columns.password.plain-columnpassword spring.shardingsphere.rules.encrypt.tables.t_Account.columns.password.cipher-columnpassword_encrypt spring.shardingsphere.rules.encrypt.tables.t_Account.columns.password.encryptor-nameencryptor_md5 # 查询是否使用密文列 spring.shardingsphere.rules.encrypt.query-with-cipher-columnfalse # 打印SQl spring.shardingsphere.props.sql.showtrue测试插入数据新增时可以看到加密后的数据和AES的有所区别查询时spring.shardingsphere.rules.encrypt.query-with-cipher-column为true时通过密文列查询由于MD5加密是非对称的所以返回的是密文数据查询时spring.shardingsphere.rules.encrypt.query-with-cipher-column为false时通过明文列查询返回明文数据2.7 分布式事务详解与实战2.7.1 什么是分布式事务2.7.1.1 本地事务介绍本地事务是指传统的单机数据库事务必须具备ACID原则原子性A所谓的原子性就是说在整个事务中的所有操作要么全部完成要么全部不做没有中间状态。对于事务在执行中发生错误所有的操作都会被回滚整个事务就像从没被执行过一样。**一致性C**事务的执行必须保证系统的一致性在事务开始之前和事务结束以后数据库的完整性没有被破坏就拿转账为例A有500元B有500元如果在一个事务里A成功转给B500元那么不管发生什么那么最后A账户和B账户的数据之和必须是1000元。**隔离性I**所谓的隔离性就是说事务与事务之间不会互相影响一个事务的中间状态不会被其他事务感知。数据库保证隔离性包括四种不同的隔离级别Read Uncommitted读取未提交内容Read Committed读取提交内容Repeatable Read可重读Serializable可串行化**持久性D**所谓的持久性就是说一旦事务提交了那么事务对数据所做的变更就完全保存在了数据库中即使发生停电系统宕机也是如此。因为在传统项目中项目部署基本是单点式即单个服务器和单个数据库。这种情况下数据库本身的事务机制就能保证ACID的原则这样的事务就是本地事务。2.7.1.2 事务日志undo和redo单个服务与单个数据库的架构中产生的事务都是本地事务。其中原子性和持久性其实是依靠undo和redo 日志来实现。InnoDB的事务日志主要分为:undo log(回滚日志提供回滚操作)redo log(重做日志提供前滚操作)1) undo log日志介绍Undo Log的原理很简单为了满足事务的原子性在操作任何数据之前首先将数据备份到Undo Log。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。Undo Log 记录了此次事务**「开始前」** 的数据状态记录的是更新之 **「前」**的值undo log 作用:实现事务原子性,可以用于回滚实现多版本并发控制MVCC, 也即非锁定读Undo log 产生和销毁Undo Log在事务开始前产生当事务提交之后undo log 并不能立马被删除而是放入待清理的链表会通过后台线程 purge thread 进行回收处理Undo Log属于逻辑日志记录一个变化过程。例如执行一个deleteundolog会记录一个insert执行一个updateundolog会记录一个相反的update。2) redo log日志介绍和Undo Log相反Redo Log记录的是新数据的备份。在事务提交前只要将Redo Log持久化即可不需要将数据持久化减少了IO的次数。Redo Log: 记录了此次事务**「完成后」** 的数据状态记录的是更新之 **「后」**的值Redo log的作用:比如MySQL实例挂了或宕机了重启时InnoDB存储引擎会使用redo log恢复数据保证数据的持久性与完整性。Redo Log 的工作原理Undo Redo事务的简化过程假设有A、B两个数据值分别为1,2A. 事务开始. B. 记录A1到undo log buffer. C. 修改A3. D. 记录A3到redo log buffer. E. 记录B2到undo log buffer. F. 修改B4. G. 记录B4到redo log buffer. H. 将undo log写入磁盘 I. 将redo log写入磁盘 J. 事务提交安全和性能问题如何保证原子性如果在事务提交前故障通过undo log日志恢复数据。如果undo log都还没写入那么数据就尚未持久化无需回滚如何保证持久化大家会发现这里并没有出现数据的持久化。因为数据已经写入redo log而redo log持久化到了硬盘因此只要到了步骤I以后事务是可以提交的。内存中的数据库数据何时持久化到磁盘因为redo log已经持久化因此数据库数据写入磁盘与否影响不大不过为了避免出现脏数据内存中与磁盘不一致事务提交后也会将内存数据刷入磁盘也可以按照固设定的频率刷新内存数据到磁盘中。redo log何时写入磁盘redo log会在事务提交之前或者redo log buffer满了的时候写入磁盘总结一下undo log 记录更新前数据用于保证事务原子性redo log 记录更新后数据用于保证事务的持久性redo log有自己的内存buffer先写入到buffer事务提交时写入磁盘redo log持久化之后意味着事务是可提交的2.7.1.3 分布式事务介绍分布式事务就是指不是在单个服务或单个数据库架构下产生的事务跨数据源的分布式事务跨服务的分布式事务综合情况1跨数据源随着业务数据规模的快速发展数据量越来越大单库单表逐渐成为瓶颈。所以我们对数据库进行了水平拆分将原单库单表拆分成数据库分片于是就产生了跨数据库事务问题。2跨服务在业务发展初期“一块大饼”的单业务系统架构能满足基本的业务需求。但是随着业务的快速发展系统的访问量和业务复杂程度都在快速增长单系统架构逐渐成为业务发展瓶颈解决业务系统的高耦合、可伸缩问题的需求越来越强烈。如下图所示按照面向服务SOA的架构的设计原则将单业务系统拆分成多个业务系统降低了各系统之间的耦合度使不同的业务系统专注于自身业务更有利于业务的发展和系统容量的伸缩。3分布式系统的数据一致性问题在数据库水平拆分、服务垂直拆分之后一个业务操作通常要跨多个数据库、服务才能完成。在分布式网络环境下我们无法保障所有服务、数据库都百分百可用一定会出现部分服务、数据库执行成功另一部分执行失败的问题。当出现部分业务操作成功、部分业务操作失败时业务数据就会出现不一致。例如电商行业中比较常见的下单付款案例包括下面几个行为创建新订单扣减商品库存从用户账户余额扣除金额完成上面的操作需要访问三个不同的微服务和三个不同的数据库。在分布式环境下肯定会出现部分操作成功、部分操作失败的问题比如订单生成了库存也扣减了但是 用户账户的余额不足这就造成数据不一致。订单的创建、库存的扣减、账户扣款在每一个服务和数据库内是一个本地事务可以保证ACID原则。但是当我们把三件事情看做一个事情事要满足保证“业务”的原子性要么所有操作全部成功要么全部失败不允许出现部分成功部分失败的现象这就是分布式系统下的事务了。此时ACID难以满足这是分布式事务要解决的问题.2.7.2 分布式事务理论2.7.2.1 CAP (强一致性)CAP 定理又被叫作布鲁尔定理。对于共享数据系统最多只能同时拥有CAP其中的两个任意两个都有其适应的场景。怎样才能同时满足CA除非是单点架构何时要满足CP对一致性要求高的场景。例如我们的Zookeeper就是这样的在服务节点间数据同步时服务对外不可用。何时满足AP对可用性要求较高的场景。例如Eureka必须保证注册中心随时可用不然拉取不到服务就可能出问题。2.7.2.2 BASE最终一致性BASE 是指基本可用Basically Available、软状态 Soft State、最终一致性 Eventual Consistency。它的核心思想是即使无法做到强一致性CAP 就是强一致性但应用可以采用适合的方式达到最终一致性。BA指的是基本业务可用性支持分区失败S表示柔性状态也就是允许短时间内不同步E表示最终一致性数据最终是一致的但是实时是不一致的。原子性和持久性必须从根本上保障为了可用性、性能和服务降级的需要只有降低一致性和隔离性的要求。BASE 解决了 CAP 理论中没有考虑到的网络延迟问题在BASE中用软状态和最终一致保证了延迟后的一致性。还以上面的下单减库存和扣款为例订单服务、库存服务、用户服务及他们对应的数据库就是分布式应用中的三个部分。CP方式现在如果要满足事务的强一致性就必须在订单服务数据库锁定的同时对库存服务、用户服务数据资源同时锁定。等待三个服务业务全部处理完成才可以释放资源。此时如果有其他请求想要操作被锁定的资源就会被阻塞这样就是满足了CP。这就是强一致弱可用AP方式三个服务的对应数据库各自独立执行自己的业务执行本地事务不要求互相锁定资源。但是这个中间状态下我们去访问数据库可能遇到数据不一致的情况不过我们需要做一些后补措施保证在经过一段时间后数据最终满足一致性。这就是高可用但弱一致最终一致。由上面的两种思想延伸出了很多的分布式事务解决方案XATCC可靠消息最终一致AT2.7.3 分布式事务模式大概了解了解了分布式事务中的强一致性和最终一致性理论下面介绍几种常见的分布式事务的解决方案。下面内容大概了解就行主要是了解分布式事务的思想2.7.3.1 DTP模型与XA协议1) DTP介绍X/Open DTP(Distributed Transaction Process)是一个分布式事务模型。这个模型主要使用了两段提交(2PC - Two-Phase-Commit)来保证分布式事务的完整性。1994 年X/Open 组织即现在的 Open Group 定义了分布式事务处理的DTP 模型。该模型包括这样几个角色应用程序 AP 我们的微服务事务管理器 TM 全局事务管理者资源管理器 RM 一般是数据库通信资源管理器 CRM 是TM和RM间的通信中间件在该模型中一个分布式事务全局事务可以被拆分成许多个本地事务运行在不同的AP和RM上。每个本地事务的ACID很好实现但是全局事务必须保证其中包含的每一个本地事务都能同时成功若有一个本地事务失败则所有其它事务都必须回滚。但问题是本地事务处理过程中并不知道其它事务的运行状态。因此就需要通过CRM来通知各个本地事务同步事务执行的状态。因此各个本地事务的通信必须有统一的标准否则不同数据库间就无法通信。XA就是 X/Open DTP中通信中间件与TM间联系的接口规范定义了用于通知事务开始、提交、终止、回滚等接口各个数据库厂商都必须实现这些接口。2) XA介绍XA是由X/Open组织提出的分布式事务的规范是基于两阶段提交协议。 XA规范主要定义了全局事务管理器TM和局部资源管理器RM之间的接口。目前主流的关系型数据库产品都是实现了XA接口。XA之所以需要引入事务管理器是因为在分布式系统中从理论上讲两台机器理论上无法达到一致的状态需要引入一个单点进行协调。由全局事务管理器管理和协调的事务可以跨越多个资源数据库和进程。事务管理器用来保证所有的事务参与者都完成了准备工作(第一阶段)。如果事务管理器收到所有参与者都准备好的消息就会通知所有的事务都可以提交了第二阶段。MySQL 在这个XA事务中扮演的是参与者的角色而不是事务管理器。2.7.3.2 2PC模式 (强一致性)二阶提交协议就是根据这一思想衍生出来的将全局事务拆分为两个阶段来执行阶段一准备阶段各个本地事务完成本地事务的准备工作。阶段二执行阶段各个本地事务根据上一阶段执行结果进行提交或回滚。这个过程中需要一个协调者coordinator还有事务的参与者voter。1正常情况投票阶段协调组询问各个事务参与者是否可以执行事务。每个事务参与者执行事务写入redo和undo日志然后反馈事务执行成功的信息agree提交阶段协调组发现每个参与者都可以执行事务agree于是向各个事务参与者发出commit指令各个事务参与者提交事务。2异常情况当然也有异常的时候投票阶段协调组询问各个事务参与者是否可以执行事务。每个事务参与者执行事务写入redo和undo日志然后反馈事务执行结果但只要有一个参与者返回的是Disagree则说明执行失败。提交阶段协调组发现有一个或多个参与者返回的是Disagree认为执行失败。于是向各个事务参与者发出abort指令各个事务参与者回滚事务。3二阶段提交的缺陷缺陷1: 单点故障问题2PC的缺点在于不能处理fail-stop形式的节点failure. 比如下图这种情况.假设coordinator和voter3都在Commit这个阶段c挂掉了, 而voter1和voter2没有收到commit消息. 这时候voter1和voter2就陷入了一个困境. 因为他们并不能判断现在是两个场景中的哪一种: (1)上轮全票通过然后voter3第一个收到了commit的消息并在commit操作之后crash了 (2)上轮voter3反对所以干脆没有通过.缺陷2: 阻塞问题在准备阶段、提交阶段每个事物参与者都会锁定本地资源并等待其它事务的执行结果阻塞时间较长资源锁定时间太久因此执行的效率就比较低了。3二阶段提交的使用场景对事务有强一致性要求对事务执行效率不敏感并且不希望有太多代码侵入。面对二阶段提交的上述缺点后来又演变出了三阶段提交但是依然没有完全解决阻塞和资源锁定的问题而且引入了一些新的问题因此实际使用的场景较少。2.7.3.3 TCC模式 (最终一致性)TCCTry-Confirm-Cancel的概念最早是由 Pat Helland 于 2007 年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出。TCC 是服务化的两阶段编程模型其 Try、Confirm、Cancel 3 个方法均由业务编码实现1) TCC的基本原理它本质是一种补偿的思路。事务运行过程包括三个方法Try资源的检测和预留Confirm执行的业务操作提交要求 Try 成功 Confirm 一定要能成功Cancel预留资源释放。执行分两个阶段准备阶段try资源的检测和预留执行阶段confirm/cancel根据上一步结果判断下面的执行方法。如果上一步中所有事务参与者都成功则这里执行confirm。反之执行cancel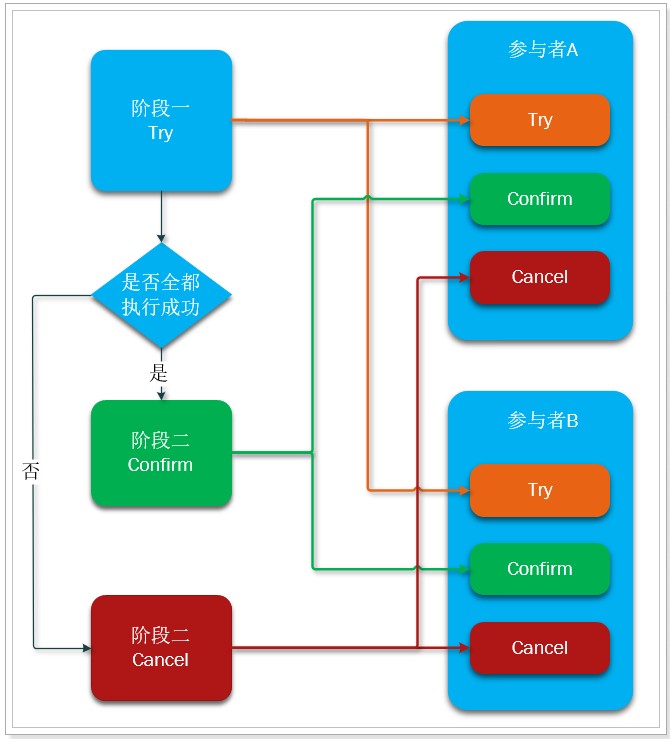粗看似乎与两阶段提交没什么区别但其实差别很大try、confirm、cancel都是独立的事务不受其它参与者的影响不会阻塞等待它人try、confirm、cancel由程序员在业务层编写锁粒度有代码控制2) TCC的具体实例我们以之前的下单业务中的扣减余额为例来看下三个不同的方法要怎么编写假设账户A原来余额是100需要余额扣减30元。如图一阶段Try余额检查并冻结用户部分金额此阶段执行完毕事务已经提交检查用户余额是否充足如果充足冻结部分余额在账户表中添加冻结金额字段值为30余额不变二阶段提交Confirm真正的扣款把冻结金额从余额中扣除冻结金额清空修改冻结金额为0修改余额为100-30 70元补偿Cancel释放之前冻结的金额并非回滚余额不变修改账户冻结金额为03) TCC模式的优势和缺点优势TCC执行的每一个阶段都会提交本地事务并释放锁并不需要等待其它事务的执行结果。而如果其它事务执行失败最后不是回滚而是执行补偿操作。这样就避免了资源的长期锁定和阻塞等待执行效率比较高属于性能比较好的分布式事务方式。缺点代码侵入需要人为编写代码实现try、confirm、cancel代码侵入较多开发成本高一个业务需要拆分成3个步骤分别编写业务实现业务编写比较复杂安全性考虑cancel动作如果执行失败资源就无法释放需要引入重试机制而重试可能导致重复执行还要考虑重试时的幂等问题4) TCC使用场景对事务有一定的一致性要求最终一致对性能要求较高开发人员具备较高的编码能力和幂等处理经验2.7.3.4 消息队列模式最终一致性消息队列的方案最初是由 eBay 提出基于TCC模式消息中间件可以基于 Kafka、RocketMQ 等消息队列。此方案的核心是将分布式事务拆分成本地事务进行处理将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或MQ中间件再通过业务规则人工发起重试。1) 事务的处理流程步骤1事务主动方处理本地事务。事务主动方在本地事务中处理业务更新操作和MQ写消息操作。例如: A用户给B用户转账,主动方先执行扣款操作步骤 2事务发起者A通过MQ将需要执行的事务信息发送给事务参与者B。例如: 告知被动方生增加银行卡金额事务主动方主动写消息到MQ事务消费方接收并处理MQ中的消息。步骤 3事务被动方通过MQ中间件通知事务主动方事务已处理的消息事务主动方根据反馈结果提交或回滚事务。例如: 订单生成成功,通知主动方法,主动放即可以提交.为了数据的一致性当流程中遇到错误需要重试容错处理规则如下当步骤 1 处理出错事务回滚相当于什么都没发生。当步骤 2 处理出错由于未处理的事务消息还是保存在事务发送方可以重试或撤销本地业务操作。如果事务被动方消费消息异常需要不断重试业务处理逻辑需要保证幂等。如果是事务被动方业务上的处理失败可以通过MQ通知事务主动方进行补偿或者事务回滚。那么问题来了我们如何保证消息发送一定成功如何保证消费者一定能收到消息2) 本地消息表为了避免消息发送失败或丢失我们可以把消息持久化到数据库中。实现时有简化版本和解耦合版本两种方式。事务发起者开启本地事务执行事务相关业务发送消息到MQ把消息持久化到数据库标记为已发送提交本地事务事务接收者接收消息开启本地事务处理事务相关业务修改数据库消息状态为已消费提交本地事务额外的定时任务定时扫描表中超时未消费消息重新发送3) 消息事务的优缺点总结上面的几种模型消息事务的优缺点如下优点业务相对简单不需要编写三个阶段业务是多个本地事务的结合因此资源锁定周期短性能好缺点代码侵入依赖于MQ的可靠性消息发起者可以回滚但是消息参与者无法引起事务回滚事务时效性差取决于MQ消息发送是否及时还有消息参与者的执行情况针对事务无法回滚的问题有人提出说可以再事务参与者执行失败后再次利用MQ通知消息服务然后由消息服务通知其他参与者回滚。那么恭喜你你利用MQ和自定义的消息服务再次实现了2PC 模型又造了一个大轮子2.7.3.5 AT模式 (最终一致性)2019年 1 月份Seata 开源了 AT 模式。AT 模式是一种无侵入的分布式事务解决方案。可以看做是对TCC或者二阶段提交模型的一种优化解决了TCC模式中的代码侵入、编码复杂等问题。在 AT 模式下用户只需关注自己的“业务 SQL”用户的 “业务 SQL” 作为一阶段Seata 框架会自动生成事务的二阶段提交和回滚操作。可以参考Seata的官方文档。1) AT模式基本原理先来看一张流程图有没有感觉跟TCC的执行很像都是分两个阶段一阶段执行本地事务并返回执行结果二阶段根据一阶段的结果判断二阶段做法提交或回滚但AT模式底层做的事情可完全不同而且第二阶段根本不需要我们编写全部有Seata自己实现了。也就是说我们写的代码与本地事务时代码一样无需手动处理分布式事务。那么AT模式如何实现无代码侵入如何帮我们自动实现二阶段代码的呢一阶段在一阶段Seata 会拦截“业务 SQL”首先解析 SQL 语义找到“业务 SQL”要更新的业务数据在业务数据被更新前将其保存成“before image”然后执行“业务 SQL”更新业务数据在业务数据更新之后再将其保存成“after image”最后获取全局行锁提交事务。以上操作全部在一个数据库事务内完成这样保证了一阶段操作的原子性。这里的before image和after image类似于数据库的undo和redo日志但其实是用数据库模拟的。update t_stock set stock stock - 2 where id 1select * from t_stock where id 1 ,保存元快照 before image ,类似undo日志.放行执行真实SQL,执行完成,再次查询,获取到最新的库存数据,再将数据保存到镜像after image 类似redo.提交业务如果成功,就清楚快照信息,失败,则根据redo 中的数据与数据库的数据进行对比,如果一致就回滚,如果不一致 出现脏数据,就需要人工介入.AT模式最重要的一点就是 程序员只需要关注业务处理的本身即可,不需要考虑回滚补偿等问题.代码写的跟以前一模一样.二阶段提交二阶段如果是提交的话因为“业务 SQL”在一阶段已经提交至数据库 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉完成数据清理即可。二阶段回滚二阶段如果是回滚的话Seata 就需要回滚一阶段已经执行的“业务 SQL”还原业务数据。回滚方式便是用“before image”还原业务数据但在还原前要首先要校验脏写对比“数据库当前业务数据”和 “after image”如果两份数据完全一致就说明没有脏写可以还原业务数据如果不一致就说明有脏写出现脏写就需要转人工处理。不过因为有全局锁机制所以可以降低出现脏写的概率。AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成用户只需编写“业务 SQL”便能轻松接入分布式事务AT 模式是一种对业务无任何侵入的分布式事务解决方案。AT模式优缺点优点与2PC相比每个分支事务都是独立提交不互相等待减少了资源锁定和阻塞时间与TCC相比二阶段的执行操作全部自动化生成无代码侵入开发成本低缺点与TCC相比需要动态生成二阶段的反向补偿操作执行性能略低于TCC2.7.3.6 Saga模式最终一致性Saga 模式是 Seata 即将开源的长事务解决方案将由蚂蚁金服主要贡献。其理论基础是Hector Kenneth 在1987年发表的论文Sagas。Seata官网对于Saga的指南https://seata.io/zh-cn/docs/user/saga.html1) 基本模型在分布式事务场景下我们把一个Saga分布式事务看做是一个由多个本地事务组成的事务每个本地事务都有一个与之对应的补偿事务。在Saga事务的执行过程中如果某一步执行出现异常Saga事务会被终止同时会调用对应的补偿事务完成相关的恢复操作这样保证Saga相关的本地事务要么都是执行成功要么通过补偿恢复成为事务执行之前的状态。自动反向补偿机制。Saga是一种补偿模式它定义了两种补偿策略向前恢复forward recovery对应于上面第一种执行顺序发生失败进行重试适用于必须要成功的场景(一定会成功)。向后恢复backward recovery对应于上面提到的第二种执行顺序发生错误后撤销掉之前所有成功的子事务使得整个 Saga 的执行结果撤销。2) 适用场景业务流程长、业务流程多参与者包含其它公司或遗留系统服务无法提供 TCC 模式要求的三个接口3) 优势一阶段提交本地事务无锁高性能事件驱动架构参与者可异步执行高吞吐补偿服务易于实现3) 缺点不保证隔离性应对方案见用户文档2.7.4 Sharding-JDBC分布式事务实战2.7.4.1 Sharding-JDBC分布式事务介绍1) 分布式内容回顾本地事务本地事务提供了 ACID 事务特性。基于本地事务为了保证数据的一致性我们先开启一个事务后才可以执行数据操作最后提交或回滚就可以了。在分布式环境下事情就会变得比较复杂。假设系统中存在多个独立的数据库为了确保数据在这些独立的数据库中保持一致我们需要把这些数据库纳入同一个事务中。这时本地事务就无能为力了我们需要使用分布式事务。分布式事务业界关于如何实现分布式事务也有一些通用的实现机制例如支持两阶段提交的 XA 协议以及以 Saga 为代表的柔性事务。针对不同的实现机制也存在一些供应商和开发工具。因为这些开发工具在使用方式上和实现原理上都有较大的差异性所以开发人员的一大诉求在于希望能有一套统一的解决方案能够屏蔽这些差异。同时我们也希望这种解决方案能够提供友好的系统集成性。2) ShardingJDBC事务ShardingJDBC支持的分布式事务方式有三种 LOCAL, XA , BASE这三种事务实现方式都是采用的对代码无侵入的方式实现的//事务类型枚举类publicenumTransactionType{//除本地事务之外还提供针对分布式事务的两种实现方案分别是 XA 事务和柔性事务LOCAL,XA,BASE}LOCAL本地事务这种方式实际上是将事务交由数据库自行管理可以用Spring的Transaction注解来配置。这种方式不具备分布式事务的特性。XA 事务XA 事务提供基于两阶段提交协议的实现机制。所谓两阶段提交顾名思义分成两个阶段一个是准备阶段一个是执行阶段。在准备阶段中协调者发起一个提议分别询问各参与者是否接受。在执行阶段协调者根据参与者的反馈提交或终止事务。如果参与者全部同意则提交只要有一个参与者不同意就终止。目前业界在实现 XA 事务时也存在一些主流工具库包括 Atomikos、Narayana 和 Bitronix。ShardingSphere 对这三种工具库都进行了集成并默认使用 Atomikos 来完成两阶段提交。BASE 事务XA 事务是典型的强一致性事务也就是完全遵循事务的 ACID 设计原则。与 XA 事务这种“刚性”不同柔性事务则遵循 BASE 设计理论追求的是最终一致性。这里的 BASE 来自基本可用Basically Available、软状态Soft State和最终一致性Eventual Consistency这三个概念。关于如何实现基于 BASE 原则的柔性事务业界也存在一些优秀的框架例如阿里巴巴提供的 Seata。ShardingSphere 内部也集成了对 Seata 的支持。当然我们也可以根据需要集成其他分布式事务类开源框架.2) 分布式事务模式整合流程ShardingSphere 作为一款分布式数据库中间件势必要考虑分布式事务的实现方案。在设计上ShardingSphere整合了XA、Saga和Seata模式后为分布式事务控制提供了极大的便利我们可以在应用程序编程时采用以下统一模式进行使用。JAVA编码方式设置事务类型ShardingSphereTransactionType(TransactionType.XA)// Sharding-jdbc一致性性事务ShardingSphereTransactionType(TransactionType.BASE)// Sharding-jdbc柔性事务2.7.4.2 环境准备下面主要演示XA事务,如下图:1) 创建数据库及表在shardingjdbc0和shardingjdbc1中分别创建职位表和职位描述表.-- 职位表CREATETABLEposition(Idbigint(11)NOTNULLAUTO_INCREMENT,namevarchar(256)DEFAULTNULL,salaryvarchar(50)DEFAULTNULL,cityvarchar(256)DEFAULTNULL,PRIMARYKEY(Id))ENGINEInnoDBDEFAULTCHARSETutf8mb4;-- 职位描述表CREATETABLEposition_detail(Idbigint(11)NOTNULLAUTO_INCREMENT,pidbigint(11)NOTNULLDEFAULT0,descriptiontext,PRIMARYKEY(Id))ENGINEInnoDBDEFAULTCHARSETutf8mb4;shardingjdbc0:shardingjdbc1:配置文件内容# 应用名称 spring.application.namesharding-jdbc-trans # 打印SQl spring.shardingsphere.props.sql-showtrue # 端口 server.port8081 #数据源配置 #配置真实的数据源 spring.shardingsphere.datasource.namesdb0,db1 #数据源1 #数据源1 spring.shardingsphere.datasource.db0.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db0.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db0.url jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db0.username root spring.shardingsphere.datasource.db0.password 123456 #数据源2 spring.shardingsphere.datasource.db1.type com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.db1.driver-class-name com.mysql.jdbc.Driver spring.shardingsphere.datasource.db1.url jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalse spring.shardingsphere.datasource.db1.username root spring.shardingsphere.datasource.db1.password 123456 #分库策略 spring.shardingsphere.rules.sharding.tables.position.database-strategy.standard.sharding-columnid spring.shardingsphere.rules.sharding.tables.position.database-strategy.standard.sharding-algorithm-nametable-mod spring.shardingsphere.rules.sharding.tables.position_detail.database-strategy.standard.sharding-columnid spring.shardingsphere.rules.sharding.tables.position_detail.database-strategy.standard.sharding-algorithm-nametable-mod #分片算法 spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.typeMOD spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count2 mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl2.7.4.3 案例实现1) entityTableName(position)DatapublicclassPosition{TableId()privatelongid;privateStringname;privateStringsalary;privateStringcity;}TableName(position_detail)DatapublicclassPositionDetail{TableId()privatelongid;privatelongpid;privateStringdescription;}3) mapperRepositorypublicinterfacePositionMapperextendsBaseMapperPosition{}RepositorypublicinterfacePositionDetailMapperextendsBaseMapperPositionDetail{}4) controllerRestControllerRequestMapping(/position)publicclassPositionController{AutowiredprivatePositionMapperpositionMapper;AutowiredprivatePositionDetailMapperpositionDetailMapper;RequestMapping(/show)publicStringshow(){returnSUCCESS;}RequestMapping(/add)publicStringsavePosition()throwsInterruptedException{PositionpositionnewPosition();position.setId(2);position.setName(root);position.setSalary(1000000);position.setCity(beijing);positionMapper.insert(position);PositionDetailpositionDetailnewPositionDetail();positionDetail.setId(1);positionDetail.setPid(position.getId());positionDetail.setDescription(root);positionDetailMapper.insert(positionDetail);returnSUCCESS;}}2.7.4.4 案例测试测试1: 访问在PositionController的add方法 , 注意: 方法不添加任何事务控制RequestMapping(/add)publicStringsavePosition()http://localhost:8081/position/add访问结果插入position的数据落在服务器1上插入position_detail的数据落在服务器2上测试2: 在方法中创造异常并在add 方法上添加Transactional本地事务控制,继续测试RequestMapping(/add)TransactionalpublicStringsavePosition()throwsInterruptedException{PositionpositionnewPosition();position.setId(2);position.setName(root);position.setSalary(1000000);position.setCity(beijing);positionMapper.insert(position);PositionDetailpositionDetailnewPositionDetail();positionDetail.setId(1);positionDetail.setPid(position.getId());positionDetail.setDescription(root);positionDetailMapper.insert(positionDetail);inta1/0;returnSUCCESS;}清除数据库中的数据再次进行测试查看数据库发现,使用Transactional注解 ,竟然实现了跨库插入数据, 出现异常也能回滚.Transactional注解可以解决分布式事务问题, 这其实是个假象接下来我们说一下为什么Transactional不能解决分布式事务问题1: 为什么会出现回滚操作 ?Sharding-JDBC中的本地事务在以下两种情况是完全支持的支持非跨库事务比如仅分表、在单库中操作支持因逻辑异常导致的跨库事务(这点非常重要)比如上述的操作跨两个库插入数据插入完成后抛出异常本地事务不支持的情况不支持因网络、硬件异常导致的跨库事务例如同一事务中跨两个库更新更新完毕后、未提交之前第一个库宕机则只有第二个库数据提交.对于因网络、硬件异常导致的跨库事务无法支持很好理解在分布式事务中无论是两阶段还是三阶段提交都是直接或者间接满足以下两个条件1.有一个事务协调者2.事务日志记录本地事务并未满足上述条件自然是无法支持为什么逻辑异常导致的跨库事务能够支持首先Sharding-JDBC中的一条SQL会经过改写拆分成不同数据源的SQL比如一条select语句会按照其中分片键拆分成对应数据源的SQL然后在不同数据源中的执行最终会提交或者回滚.下面是Sharding-JDBC自定义实现的事务控制类ShardingConnection 的类关系图可以看到ShardingConnection继承了java.sql.Connection,Connection是数据库连接对象,也可以对数据库的本地事务进行管理.找到ShardingConnection的rollback方法rollback的方法中区分了本地事务和分布式事务如果是本地事务将调用父类的rollback方法如下ShardingConnection父类AbstractConnectionAdapter#rollbackForceExecuteTemplate#execute()方法内部就是遍历数据源去执行对应的rollback方法publicvoidexecute(CollectionTtargets,ForceExecuteCallbackTcallback)throwsSQLException{CollectionSQLExceptionexceptionsnewLinkedList();Iteratorvar4targets.iterator();while(var4.hasNext()){Objecteachvar4.next();try{callback.execute(each);}catch(SQLExceptionvar7){exceptions.add(var7);}}this.throwSQLExceptionIfNecessary(exceptions);}总结: 依靠Spring的本地事务Transactional是无法保证跨库的分布式事务rollback 在各个数据源中回滚且未记录任何事务日志因此在非硬件、网络的情况下都是可以正常回滚的一旦因为网络、硬件故障可能导致某个数据源rollback失败这样即使程序恢复了正常也无undo日志继续进行rollback因此这里就造成了数据不一致了。3)测试3: 实现XA事务首先要在项目中导入对应的依赖包dependencygroupIdorg.apache.shardingsphere/groupIdartifactIdshardingsphere-transaction-xa-core/artifactIdversion5.1.1/version/dependencydependencygroupIdcom.atomikos/groupIdartifactIdtransactions-jta/artifactIdversion4.0.4/version/dependency创建配置类ConfigurationEnableTransactionManagementpublicclassTransactionConfiguration{BeanpublicPlatformTransactionManagertxManager(finalDataSourcedataSource){returnnewDataSourceTransactionManager(dataSource);}BeanpublicJdbcTemplatejdbcTemplate(finalDataSourcedataSource){returnnewJdbcTemplate(dataSource);}}我们知道ShardingSphere 提供的事务类型有三种分别是 LOCAL、XA 和 BASE默认使用的是 LOCAL。所以如果需要用到分布式事务需要在业务方法上显式的添加这个注解ShardingTransactionType(TransactionType.XA)RequestMapping(/add)ShardingSphereTransactionType(TransactionType.XA)TransactionalpublicStringsavePosition()throwsInterruptedException{PositionpositionnewPosition();position.setId(2);position.setName(root);position.setSalary(1000000);position.setCity(beijing);positionMapper.insert(position);PositionDetailpositionDetailnewPositionDetail();positionDetail.setId(1);positionDetail.setPid(position.getId());positionDetail.setDescription(root);positionDetailMapper.insert(positionDetail);inta1/0;returnSUCCESS;}执行测试代码,结果是数据库的插入全部被回滚了.2.8 ShardingProxy实战Sharding-Proxy是ShardingSphere的第二个产品定位为透明化的数据库代理端提供封装了数据库二进制协议的服务端版本用于完成对异构语言的支持。 目前先提供MySQL版本它可以使用任何兼容MySQL协议的访问客户端(如MySQL Command Client, MySQL Workbench等操作数据对DBA更加友好。向应用程序完全透明可直接当做MySQL使用适用于任何兼容MySQL协议的客户端2.8.1 使用二进制发布包安装ShardingSphere-Proxy目前 ShardingSphere-Proxy 提供了 3 种获取方式二进制发布包DockerHelm这里我们使用二进制包的形式安装ShardingProxy, 这种安装方式既可以Linux系统运行又可以在windows系统运行,步骤如下:1) 解压二进制包官方文档:https://shardingsphere.apache.org/document/5.1.1/cn/user-manual/shardingsphere-proxy/startup/bin/安装包下载https://archive.apache.org/dist/shardingsphere/5.1.1/解压windows使用解压软件解压文件Linux将文件上传至/opt目录并解压tar-zxvf apache-shardingsphere-5.1.1-shardingsphere-proxy-bin.tar.gz2) 上传MySQL驱动下载地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java/8.0.22mysql-connector-java-8.0.22.jar ,将MySQl驱动放至ext-lib目录 ,该ext-lib目录需要自行创建,创建位置如下图: 3) 修改配置conf/server.yaml# 配置用户信息 用户名密码,赋予管理员权限rules:-!AUTHORITYusers:-root%:rootprovider:type:ALL_PRIVILEGES_PERMITTED#开启SQL打印props:sql-show:true4) 启动ShardingSphere-ProxyLinux 操作系统请运行bin/start.shWindows 操作系统请运行bin/start.bat指定端口号和配置文件目录bin/start.bat ${proxy_port} ${proxy_conf_directory}5) 远程连接ShardingSphere-Proxy远程访问,默认端口3307mysql -h192.168.116.129 -P3307 -uroot -p6) 访问测试showdatabases;可以看到一些基础的表信息2.8.2 proxy实现读写分离1) 修改配置config-readwrite-splitting.yaml#schemaName用来指定-逻辑表名schemaName:readwrite_splitting_dbdataSources:write_ds:url:jdbc:mysql://192.168.116.129:3306/shardingjdbc1?characterEncodingUTF-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1read_ds_0:url:jdbc:mysql://192.168.116.128:3306/shardingjdbc0?characterEncodingUTF-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1rules:-!READWRITE_SPLITTINGdataSources:readwrite_ds:type:Staticprops:write-data-source-name:write_dsread-data-source-names:read_ds_02) 命令行测试C:\Users\86187mysql-h192.168.116.129-P3307-uroot-p mysqlshowdatabases;------------------------|schema_name|------------------------|readwrite_splitting_db||mysql||information_schema||performance_schema||sys|------------------------5rowsinset(0.03sec)mysqlusereadwrite_splitting_db;Databasechanged mysqlshowtables;----------------------------------------------|Tables_in_readwrite_splitting_db|Table_type|----------------------------------------------|t_course_0|BASETABLE||t_order_item_0|BASETABLE||t_order_item_1|BASETABLE||t_order_0|BASETABLE||position|BASETABLE||t_order_1|BASETABLE||t_district|BASETABLE||position_detail|BASETABLE||t_course_1|BASETABLE||products|BASETABLE|----------------------------------------------10rowsinset(0.00sec)mysqlselect*fromt_order_0;---------------------------------------------------------------------------------------|order_id|user_id|product_name|total_price|status|create_time|---------------------------------------------------------------------------------------|378522667419959296|2|iPhone15Pro|8999.00|CREATED|2025-09-2020:33:57||378522667549982720|4|iPhone15Pro|8999.00|CREATED|2025-09-2020:33:57||378522667696783360|6|iPhone15Pro|8999.00|CREATED|2025-09-2020:33:57||378522667839389696|8|iPhone15Pro|8999.00|CREATED|2025-09-2020:33:57||378522667935858688|10|iPhone15Pro|8999.00|CREATED|2025-09-2020:33:57|---------------------------------------------------------------------------------------5rowsinset(0.07sec)3) 动态查看日志tail -f /opt/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin/logs/stdout.log2.8.3 使用应用程序连接proxy1) 创建项目项目名称: shardingproxySpring脚手架: http://start.aliyun.com2) 添加依赖parentgroupIdorg.springframework.boot/groupIdartifactIdspring-boot-starter-parent/artifactIdversion2.3.7.RELEASE/versionrelativePath//parentgroupIdcom.zhp/groupIdartifactIdshardingproxy/artifactIdversion1.0-SNAPSHOT/versiondependenciesdependencygroupIdorg.springframework.boot/groupIdartifactIdspring-boot-starter-web/artifactId/dependencydependencygroupIdmysql/groupIdartifactIdmysql-connector-java/artifactIdscoperuntime/scope/dependencydependencygroupIdcom.baomidou/groupIdartifactIdmybatis-plus-boot-starter/artifactIdversion3.3.1/version/dependencydependencygroupIdorg.projectlombok/groupIdartifactIdlombok/artifactIdoptionaltrue/optional/dependencydependencygroupIdorg.springframework.boot/groupIdartifactIdspring-boot-starter-test/artifactIdscopetest/scopeexclusionsexclusiongroupIdorg.junit.vintage/groupIdartifactIdjunit-vintage-engine/artifactId/exclusion/exclusions/dependency/dependencies3) 创建实体类TableName(products)DatapublicclassProducts{TableId(valuepid,typeIdType.AUTO)privateLongpid;privateStringpname;privateintprice;privateStringflag;}4) 创建MapperMapperpublicinterfaceProductsMapperextendsBaseMapperProducts{}5) 配置数据源# 应用名称 spring.application.namesharding-proxy-demo #mysql数据库 (实际连接的是proxy) spring.datasource.driver-class-namecom.mysql.jdbc.Driver spring.datasource.urljdbc:mysql://192.168.116.129:3307/readwrite_splitting_db?serverTimezoneGMT%2B8useSSLfalsecharacterEncodingutf-8 spring.datasource.usernameroot spring.datasource.passwordroot #mybatis日志 mybatis-plus.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl6) 启动类SpringBootApplicationpublicclassShardingproxyApplication{publicstaticvoidmain(String[]args){SpringApplication.run(ShardingproxyApplication.class,args);}}7) 测试SpringBootTestclassShardingproxyDemoApplicationTests{AutowiredprivateProductsMapperproductsMapper;/** * 读数据测试 */TestpublicvoidtestSelect(){productsMapper.selectList(null).forEach(System.out::println);}TestpublicvoidtestInsert(){ProductsproductsnewProducts();products.setPname(洗碗机);products.setPrice(1000);products.setFlag(1);productsMapper.insert(products);}}日志2.8.4 Proxy实现垂直分片1) 修改配置config-sharding.yamlschemaName:sharding_db#dataSources:ds_0:url:jdbc:mysql://192.168.116.128:3306/payorder_db?characterEncodingUTF-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1ds_1:url:jdbc:mysql://192.168.116.129:3306/user_db?characterEncodingUTF-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1rules:-!SHARDINGtables:pay_order:actualDataNodes:ds_0.pay_orderusers:actualDataNodes:ds_1.users重新启动proxy2) 动态查看日志tail -f /opt/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin/logs/stdout.log3) 远程访问mysql-h192.168.116.129-P3307-uroot-p mysqlshowdatabases;------------------------|schema_name|------------------------|sharding_db||readwrite_splitting_db||mysql||information_schema||performance_schema||sys|------------------------6rowsinset(0.00sec)mysqlusesharding_db;Databasechanged mysqlshowtables;-----------------------------------|Tables_in_sharding_db|Table_type|-----------------------------------|pay_order|BASETABLE||users|BASETABLE|-----------------------------------2rowsinset(0.01sec)mysqlselect*frompay_order;----------------------------------------|order_id|user_id|product_name|COUNT|----------------------------------------|2001|1003|电视|0|----------------------------------------1rowinset(0.09sec)2.8.5 Proxy实现水平分片1) 修改配置config-sharding.yamlschemaName:sharding_dbdataSources:course_db0:url:jdbc:mysql://192.168.116.128:3306/course_db0?useUnicodetruecharacterEncodingutf-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1course_db1:url:jdbc:mysql://192.168.116.129:3306/course_db1?useUnicodetruecharacterEncodingutf-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1rules:-!SHARDINGtables:t_course:actualDataNodes:course_db${0..1}.t_course_${0..1}databaseStrategy:standard:shardingColumn:user_idshardingAlgorithmName:alg_modtableStrategy:standard:shardingColumn:cidshardingAlgorithmName:alg_hash_modkeyGenerateStrategy:column:cidkeyGeneratorName:snowflakeshardingAlgorithms:alg_mod:type:MODprops:sharding-count:2alg_hash_mod:type:HASH_MODprops:sharding-count:2keyGenerators:snowflake:type:SNOWFLAKE重新启动proxy2) 远程访问mysqlusesharding_db;Databasechanged mysqlshowtables;-----------------------------------|Tables_in_sharding_db|Table_type|-----------------------------------|t_district|BASETABLE||t_course|BASETABLE|-----------------------------------2rowsinset(0.00sec)mysqlselect*fromt_course;3) 动态查看日志tail -f /opt/apache-shardingsphere-5.1.1-shardingsphere-proxy-bin/logs/stdout.log2.8.6 Proxy实现广播表环境准备1) 修改配置config-sharding.yamlschemaName:sharding_dbdataSources:course_db0:url:jdbc:mysql://192.168.116.128:3306/course_db0?useUnicodetruecharacterEncodingutf-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1course_db1:url:jdbc:mysql://192.168.116.129:3306/course_db1?useUnicodetruecharacterEncodingutf-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1rules:-!SHARDINGtables:t_course:actualDataNodes:course_db${0..1}.t_course_${0..1}databaseStrategy:standard:shardingColumn:user_idshardingAlgorithmName:alg_modtableStrategy:standard:shardingColumn:cidshardingAlgorithmName:alg_hash_modkeyGenerateStrategy:column:cidkeyGeneratorName:snowflakebroadcastTables:-t_districtshardingAlgorithms:alg_mod:type:MODprops:sharding-count:2alg_hash_mod:type:HASH_MODprops:sharding-count:2keyGenerators:snowflake:type:SNOWFLAKE重启proxy2) 测试广播表INSERTINTOt_district(id,district_name,LEVEL)VALUES(1,北京,1);2.8.7 Proxy实现绑定表环境准备server01:server02:1) 修改配置config-sharding.yamlschemaName:sharding_dbdataSources:db0:url:jdbc:mysql://192.168.116.128:3306/shardingjdbc0?useUnicodetruecharacterEncodingutf-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1db1:url:jdbc:mysql://192.168.116.129:3306/shardingjdbc1?useUnicodetruecharacterEncodingutf-8useSSLfalseusername:rootpassword:123456connectionTimeoutMilliseconds:30000idleTimeoutMilliseconds:60000maxLifetimeMilliseconds:1800000maxPoolSize:50minPoolSize:1rules:-!SHARDINGtables:t_order:actualDataNodes:db$-{0..1}.t_order_$-{0..1}databaseStrategy:standard:shardingColumn:user_idshardingAlgorithmName:alg_modtableStrategy:standard:shardingColumn:order_IdshardingAlgorithmName:alg_hash_modkeyGenerateStrategy:column:cidkeyGeneratorName:snowflaket_order_item:actualDataNodes:db$-{0..1}.t_order_item_$-{0..1}databaseStrategy:standard:shardingColumn:user_IdshardingAlgorithmName:alg_modtableStrategy:standard:shardingColumn:order_IdshardingAlgorithmName:alg_hash_modkeyGenerateStrategy:column:idkeyGeneratorName:snowflakebindingTables:-t_order,t_order_itemshardingAlgorithms:alg_mod:type:MODprops:sharding-count:2alg_hash_mod:type:HASH_MODprops:sharding-count:2keyGenerators:snowflake:type:SNOWFLAKE重启proxy2) 测试绑定表SELECTt_order.order_Id,t_order.product_name,t_order_item.quantityFROMt_orderINNERjoint_order_itemont_order.order_Idt_order_item.order_Id;2.8.8 总结Sharding-Proxy的优势在于对异构语言的支持(无论使用什么语言就都可以访问)以及为DBA提供可操作入口。Sharding-Proxy 默认不支持hint如需支持请在conf/server.yaml中将props的属性proxy.hint.enabled设置为true。在Sharding-Proxy中HintShardingAlgorithm的泛型只能是String类型。Sharding-Proxy默认使用3307端口可以通过启动脚本追加参数作为启动端口号。如: bin/start.sh 3308Sharding-Proxy使用conf/server.yaml配置注册中心、认证信息以及公用属性。Sharding-Proxy支持多逻辑数据源每个以config-做前缀命名yaml配置文件即为一个逻辑数据源。