2026/1/9 16:42:53
网站建设
项目流程
网站开发实践教程,怎么做刷东西网站,分销是什么意思,网页设计模板html代码7行5列简介
RAPTOR是一种递归抽象处理技术#xff0c;通过构建层次化知识索引#xff0c;将RAG系统从简单文档块检索升级为类似人脑的知识组织方式。它通过聚类抽象、LLM总结和递归构建#xff0c;将原始文档块组织成包含多粒度信息的知识树#xff0c;大幅提升检索性能#xf…简介RAPTOR是一种递归抽象处理技术通过构建层次化知识索引将RAG系统从简单文档块检索升级为类似人脑的知识组织方式。它通过聚类抽象、LLM总结和递归构建将原始文档块组织成包含多粒度信息的知识树大幅提升检索性能减少Token使用量达70%有效解决大型知识库的精准定位和上下文理解问题为RAG技术带来革命性改进。你或许已经对RAG(Retrieval Augmented Generation检索增强生成) 这个词耳熟能详。它就像一个超级大脑能让大语言模型LLM通过检索外部知识回答那些训练时没“见过”的问题。从简单的问答机器人到复杂的知识库助手RAG的应用无处不在。然而RAG也并非完美无缺。随着你提供的知识库越来越庞大问题也随之而来知识库里信息太多怎么精准定位到最相关的几条那些看似无关但实则紧密相连的“上下文”怎么办当一个概念被不同的人用不同的方式描述时如何让RAG把它们“认出来”我们通常会用各种优化技巧来解决这些问题查询转换、重排模型、多路检索……但每增加一层系统就变得更复杂调用LLM的次数也越多整个架构像搭积木一样摇摇欲坠。那么有没有一种方法能从源头解决问题不增加查询时的复杂性而是让知识库本身就变得更“聪明”这正是RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval递归抽象处理树形组织检索)管道的核心思想。它不改变你查询的方式而是通过构建一个层次化的索引让知识库像人脑一样从细节到高层概念逐层理解和组织信息。这个方法到底有多神它能在不增加查询复杂度的前提下大幅提升检索性能甚至可能让你的RAG系统少用70%的Token从而节省计算和金钱成本。今天我们就来深入剖析RAPTOR看看它是如何通过一个巧妙的“递归抽象”过程构建出“聪明”的知识索引从而彻底颠覆传统RAG。一、RAPTOR从“叶子”到“树干”构建智慧知识库简单来说RAPTOR 就像一个图书馆管理员但它不只是简单地把书本文档堆在一起而是先将书本拆解然后根据主题归类再为每类主题写摘要最后把这些摘要和原始书页一起整理成一本“精要合集”。这个过程可以拆解为几个核心步骤创建“叶节点”首先将所有原始文档切分成一个个小而详细的文本块。这些文本块就像一棵大树的“叶子”是知识最基本的组成单元。传统的RAG检索通常只停留在这一步直接对这些“叶子”进行向量化并搜索。聚类抽象接下来利用机器学习聚类算法将语义相关的“叶子”自动分组。比如所有讨论“模型训练参数”的叶子都会被分到同一组。LLM总结使用LLM为每个聚类生成一个简洁、高质量的摘要。这些摘要成了这棵知识树的下一个更高层级的“分支”。它概括了本组“叶子”的核心思想。递归向上重复步骤2和3。对新生成的摘要进行聚类和总结不断向上构建直到到达一个能代表整个文档库最高层概念的“根节点”。索引全部最后将所有内容——原始的“叶节点”和所有生成的摘要——全部索引到一个向量数据库中。这样检索时就能在一个“多分辨率”的知识库中进行搜索。这个“从下到上”的构建过程让RAPTOR管道能够处理不同粒度的查询。当用户问一个具体问题时它可以检索到精确的“叶子”当用户问一个宏观概念时它可以直接检索到高层级的摘要避免“只见树叶不见森林”的问题。接下来我们将通过一个真实的案例——使用Hugging Face的官方文档来构建知识库——来深入探究RAPTOR的强大之处。二、配置RAG环境准备工作为了公平地评估RAPTOR的性能我们选择使用一年前发布的、经过量化的旧模型而不是最新的LLM。这样做的目的是为了确保评估真正考验的是检索质量而不是模型本身是否“知道”答案。首先让我们导入所需的库并配置好LLM和Embedding模型。# Import the core PyTorch library for tensor operationsimport torch# Import LangChains wrappers for Hugging Face modelsfrom langchain_huggingface import HuggingFaceEmbeddings, HuggingFacePipeline# Import core components from the transformers library for model loading and configurationfrom transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, BitsAndBytesConfig# Import LangChains tools for prompt engineering and output handlingfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParser我们将使用sentence-transformers/all-MiniLM-L6-v2作为嵌入模型因为它轻量且高效非常适合大规模文档索引。# --- Configure Embedding Model ---embedding_model_name sentence-transformers/all-MiniLM-L6-v2# Use GPU if available, otherwise fallback to CPUmodel_kwargs {device: cuda}# Initialize embeddings with LangChains wrapperembeddings HuggingFaceEmbeddings( model_nameembedding_model_name, model_kwargsmodel_kwargs)对于文本生成我们选择Mistral-7B-Instruct-v0.2这是一个功能强大但体积紧凑的指令微调模型。为了在显存有限的设备上运行我们使用4-bit量化技术来加载它。# --- Configure LLM for Summarization and Generation ---llm_id mistralai/Mistral-7B-Instruct-v0.2# Quantization: reduces memory footprint while preserving performancequantization_config BitsAndBytesConfig( load_in_4bitTrue, bnb_4bit_compute_dtypetorch.float16, bnb_4bit_quant_typenf4)# Load tokenizertokenizer AutoTokenizer.from_pretrained(llm_id)# Load LLM with quantizationmodel AutoModelForCausalLM.from_pretrained( llm_id, torch_dtypetorch.float16, device_mapauto, quantization_configquantization_config)加载模型和分词器后我们将它们封装进一个Hugging Face管道以便进行文本生成。# Create a text-generation pipeline using the loaded model and tokenizer.pipe pipeline( text-generation, modelmodel, tokenizertokenizer, max_new_tokens512 # Controls the max length of the generated summaries and answers)# Wrap pipeline for LangChain compatibilityllm HuggingFacePipeline(pipelinepipe)至此我们已经配置好了RAG管道所需的两个核心组件接下来我们将准备用于测试的知识库。针对所有自学遇到困难的同学们我帮大家系统梳理大模型学习脉络将这份LLM大模型资料分享出来包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 有需要的小伙伴可以扫描下方二维码领取↓↓↓三、数据准备抓取Hugging Face文档并分析为了充分展示RAPTOR的优势我们需要一个复杂且具有挑战性的知识库。我们选择抓取Hugging Face的官方文档因为其中充满了重叠信息和微妙的差异。例如Hugging Face对ZeRO-3检查点保存有多种描述方式trainer.save_model()、unwrap_model().save_pretrained()和zero_to_fp32()。这些都指向同一个底层概念即将模型分片整合为一个完整的检查点。一个简单的RAG管道可能只会检索到其中一种变体从而导致信息不完整。我们将抓取以下五个核心指南的文档内容# Define the documentation sections to scrape, with varying crawl depths.urls_to_load [ {url: https://huggingface.co/docs/transformers/index, max_depth: 3}, {url: https://huggingface.co/docs/datasets/index, max_depth: 2}, {url: https://huggingface.co/docs/tokenizers/index, max_depth: 2}, {url: https://huggingface.co/docs/peft/index, max_depth: 1}, {url: https://huggingface.co/docs/accelerate/index, max_depth: 1}] 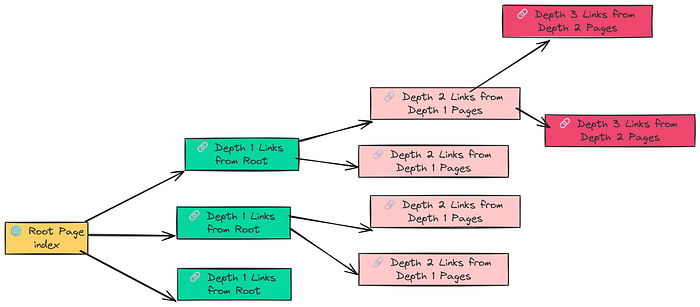 使用 RecursiveUrlLoader 和 BeautifulSoup 来抓取内容 plaintext from langchain_community.document_loaders import RecursiveUrlLoaderfrom bs4 import BeautifulSoup as Soup# Empty list to append componentsdocs []# Iterate through the list and crawl each documentation section.for item in urls_to_load: # Initialize the loader with the specific URL and parameters. loader RecursiveUrlLoader( urlitem[url], max_depthitem[max_depth], extractorlambda x: Soup(x, html.parser).text, # Use BeautifulSoup to extract text prevent_outsideTrue, # Ensure we stay within the documentation pages use_asyncTrue, # Use asynchronous requests for faster crawling timeout600, # Set a generous timeout for slow pages ) # Load the documents and add them to our master list. loaded_docs loader.load() docs.extend(loaded_docs) print(fLoaded {len(loaded_docs)} documents from {item[url]})运行后我们得到了145个文档总计312,566个Token。对文档的Token分布进行分析后我们发现很多文档都非常长最大达到12,453个Token这表明需要进行合理的分块chunking。import numpy as np# We need a consistent way to count tokens,usingthe LLMs tokenizer is the most accurate method.defcount_tokens(text:str)-int:Counts the number of tokens in a text using the configured tokenizer.# Ensure text isnotNoneandis a string ifnotisinstance(text,str):return0returnlen(tokenizer.encode(text))# Extract the text content from the loaded LangChain Document objectsdocs_texts[d.page_contentford in docs]# Calculate token countsforeach documenttoken_counts[count_tokens(text)fortext in docs_texts]# Print statistics to understand the document sizedistributionprint(fTotal documents: {len(docs_texts)})print(fTotal tokens in corpus: {np.sum(token_counts)})print(fAverage tokens per document: {np.mean(token_counts):.2f})print(fMin tokens in a document: {np.min(token_counts)})print(fMax tokens in a document: {np.max(token_counts)})# Output# Total documents:145# Total tokens in corpus:312566# Average tokens per document:2155.59# Min tokens in a document:312# Max tokens in a document:12453从Token分布直方图来看文档的Token数量中位数大约在1000左右。因此我们将chunk_size设置为1000。四、传统RAG的“硬伤”为什么会“答非所问”为了证明RAPTOR的优越性我们需要一个参照物一个最基础的、没有优化的RAG系统。这个系统将使用和RAPTOR相同的模型和知识库唯一的区别在于它只对原始文档块即我们前面提到的“叶节点”进行索引。首先我们利用RecursiveCharacterTextSplitter将文档切分成一个个叶节点from langchain.text_splitter import RecursiveCharacterTextSplitter# We join all the documents into a single stringformore efficient processing.# The---separator helps maintain document boundariesifneeded later.concatenated_content\n\n --- \n\n.join(docs_texts)# Create the text splitterusingour LLMs tokenizerforaccuracy.text_splitterRecursiveCharacterTextSplitter.from_huggingface_tokenizer(tokenizertokenizer,chunk_size1000,# The max number of tokens in a chunk chunk_overlap100# The number of tokens to overlap between chunks)# Split the text into chunks,which will be our leaf nodes.leaf_textstext_splitter.split_text(concatenated_content)print(fCreated {len(leaf_texts)} leaf nodes (chunks) for the RAPTOR tree.)# Output# Created412leafnodes(chunks)forthe RAPTOR tree.接下来我们构建一个简单的RAG管道并使用FAISS进行向量存储。from langchain_community.vectorstores import FAISSfrom langchain_core.runnables import RunnablePassthrough# In a simple RAG,the vector store is built only on the leaf-level chunks.vectorstore_normalFAISS.from_texts(textsleaf_texts,embeddingembeddings)# Create a retriever fromthisvector store that fetches the top5results.retriever_normalvectorstore_normal.as_retriever(search_kwargs{k:5})print(fBuilt Simple RAG vector store with {len(leaf_texts)} documents.)# Output# Built Simple RAG vector store with412documents.现在我们构建完整的RAG链并提出一个宏观、概念性的问题#This prompttemplateinstructs the LLM to answer based ONLY on the provided context.final_prompt_textYou are an expert assistant for the Hugging Face ecosystem. Answer the users question based ONLY on the following context. If the context does not contain the answer, state that you dont know.CONTEXT:{context}QUESTION:{question}ANSWER:final_promptChatPromptTemplate.from_template(final_prompt_text)# A helper function to format the retrieved documents.defformat_docs(docs):return\n\n.join(doc.page_contentfordoc in docs)# Construct the RAG chainforthe simple approach.rag_chain_normal({context:retriever_normal|format_docs,question:RunnablePassthrough()}|final_prompt|llm|StrOutputParser())# Lets ask a broad,conceptual question.questionWhat is the core philosophy of the Hugging Face ecosystem?answerrag_chain_normal.invoke(question)print(fQuestion: {question}\n)print(fAnswer: {answer})我们来看看这个简单RAG的输出Question: What is the core philosophy of the Hugging Face ecosystem?Answer: The Hugging Face ecosystem is built around the transformers library, which provides APIs to easily download and use pretrained models.The core idea is to make these models accessible. For example, the pipelinefunction is a key part of this, offering a simple way to use models for inference. It also includes libraries like datasets for data loading andaccelerate for training.这个回答没错但它给人的感觉是零散的、缺乏整体感的。它像是一堆“正确”的事实被硬生生地拼凑在一起没有真正理解背后的宏大叙事。这就是典型的“迷失在细节中”的问题。检索器只抓住了关键词却错过了核心思想。而这正是RAPTOR要解决的痛点。五、揭秘RAPTOR的“智慧大脑”层次化聚类引擎RAPTOR的魔法在于它能够将零散的“叶子”组织成有意义的“分支”这个过程离不开一个精巧的“层次化聚类引擎”。这个引擎由三个核心组件构成1. UMAP降维打击看清数据的“真实形状”我们的文本嵌入embeddings通常存在于一个高维空间中比如384维。在这个空间里数据点之间很拥挤很难看出它们的真实关系这就是所谓的“维度诅咒”。UMAP(Uniform Manifold Approximation and Projection统一流形近似与投影) 就像一个强大的透视镜能将这些高维数据投影到更低的维度比如10维同时最大限度地保持数据点之间的语义关系。这就像把一张复杂的立体地图变成一张清晰的平面地图让聚类算法能够更轻松地识别出数据的“形状”和“分组”。from typing import Dict, List, Optional, Tupleimport numpy as npimport pandas as pdimport umapfrom sklearn.mixture import GaussianMixtureRANDOM_SEED 42def global_cluster_embeddings(embeddings: np.ndarray, dim: int, n_neighbors: Optional[int] None, metric: str cosine) - np.ndarray: Perform global dimensionality reduction on the embeddings using UMAP. # Heuristically set n_neighbors if not provided if n_neighbors isNone: n_neighbors int((len(embeddings) - 1) ** 0.5) # Return the UMAP-transformed embeddings return umap.UMAP( n_neighborsn_neighbors, n_componentsdim, metricmetric, random_stateRANDOM_SEED ).fit_transform(embeddings)2. GMM BIC让数据自己决定“分几组”我们该把文档分为5个、10个还是50个主题凭空猜测一个数字K值显然是不合理的。RAPTOR采取了更科学的方法使用GMM(Gaussian Mixture Model高斯混合模型) 和BIC(Bayesian Information Criterion贝叶斯信息准则)。这个过程就像一个实验第一步我们尝试将数据拟合到不同数量的簇中比如从1个到50个。第二步每次拟合后计算出一个BIC分数。BIC 既能衡量模型对数据的拟合程度又会惩罚过于复杂的模型即惩罚簇的数量。第三步我们选择那个 BIC 分数最低的簇数量因为它代表了模型在“拟合”和“简洁”之间找到了最佳平衡。def get_optimal_clusters(embeddings: np.ndarray, max_clusters: int 50) - int: Determine the optimal number of clusters using the Bayesian Information Criterion (BIC). # Limit the max number of clusters to be less than the number of data points max_clusters min(max_clusters, len(embeddings)) # If theres only one point, there can only be one cluster if max_clusters 1: return1 # Test different numbers of clusters from 1 to max_clusters n_clusters_range np.arange(1, max_clusters) bics [] for n in n_clusters_range: # Initialize and fit the GMM for the current number of clusters gmm GaussianMixture(n_componentsn, random_stateRANDOM_SEED) gmm.fit(embeddings) # Calculate and store the BIC for the current model bics.append(gmm.bic(embeddings)) # Return the number of clusters that resulted in the lowest BIC score return n_clusters_range[np.argmin(bics)]3. GMM概率软分配允许“脚踏两条船”传统的聚类算法如K-Means是“硬聚类”它强制将每个数据点分到且只分到一个簇里。但现实情况是一个文档块可能同时讨论“模型训练”和“数据预处理”它理应同时属于这两个主题。GMM能够实现“软聚类”。它不直接分配而是计算每个文档块属于每个簇的概率。通过设置一个概率阈值我们可以让一个文档块同时被分配到多个相关的簇中。这完美地模拟了知识之间的交叉和关联。def GMM_cluster(embeddings: np.ndarray, threshold: float) - Tuple[List[np.ndarray], int]: Cluster embeddings using a GMM and a probability threshold. # Find the optimal number of clusters for this set of embeddings n_clusters get_optimal_clusters(embeddings) # Fit the GMM with the optimal number of clusters gmm GaussianMixture(n_componentsn_clusters, random_stateRANDOM_SEED) gmm.fit(embeddings) # Get the probability of each point belonging to each cluster probs gmm.predict_proba(embeddings) # Assign a point to a cluster if its probability is above the threshold # A single point can be assigned to multiple clusters. labels [np.where(prob threshold)[0] for prob in probs] return labels, n_clusters这个“层次化聚类引擎”将 UMAP、BIC 和 GMM 精巧地组合在一起确保了RAPTOR能够准确、有深度地理解和组织知识。六、构建和运行RAPTOR树从理论到实践有了这套强大的聚类引擎我们现在可以将它应用到RAPTOR的构建过程中。这个过程分为两个阶段全局聚类首先对我们所有的412个叶节点进行一次整体的降维和聚类。这一步的目的是找出文档库中最高层级的主题比如“Transformers库”、“Datasets库”和“训练与优化”。局部聚类接下来我们“放大”每个全局簇。例如进入“训练与优化”这个簇对它内部的文档再次进行降维和聚类。这一次我们会找到更细分的子主题比如“PEFT”、“Accelerate”和“Trainer参数”。这个“先概览后细看”的RAPTOR策略完美地模拟了人类的思考过程。它首先建立起知识的宏观框架然后再填充细节。我们编写一个名为perform_clustering的函数来整合上述所有步骤实现这个分层的聚类逻辑。def perform_clustering(embeddings: np.ndarray, dim: int 10, threshold: float 0.1) - List[np.ndarray]: Perform hierarchical clustering (global and local) on the embeddings. # Handle cases with very few documents to avoid errors during dimensionality reduction. if len(embeddings) dim 1: return [np.array([0]) for _ in range(len(embeddings))] # --- Global Clustering Stage --- # First, reduce the dimensionality of all embeddings globally. reduced_embeddings_global global_cluster_embeddings(embeddings, dim) # Then, perform GMM clustering on the reduced-dimensional data. global_clusters, n_global_clusters GMM_cluster(reduced_embeddings_global, threshold) # --- Local Clustering Stage --- # Initialize a list to hold all final local cluster assignments for each document. all_local_clusters [np.array([]) for _ in range(len(embeddings))] # Keep track of the total number of clusters found so far to ensure unique IDs. total_clusters 0 # Iterate through each global cluster to find sub-clusters. for i in range(n_global_clusters): # Get all original indices for embeddings that are part of the current global cluster. global_cluster_indices [idx for idx, gc in enumerate(global_clusters) if i in gc] ifnot global_cluster_indices: continue # Get the actual embeddings for this global cluster. global_cluster_embeddings_ embeddings[global_cluster_indices] # Perform local clustering on this subset of embeddings. if len(global_cluster_embeddings_) dim 1: local_clusters, n_local_clusters ([np.array([0])] * len(global_cluster_embeddings_)), 1 else: # We dont need a separate local_cluster_embeddings function. # The global one works, as it adapts n_neighbors to the input reduced_embeddings_local global_cluster_embeddings(global_cluster_embeddings_, dim) local_clusters, n_local_clusters GMM_cluster(reduced_embeddings_local, threshold) # Map the local cluster IDs back to the original document indices. for original_idx, local_cluster_ids in zip(global_cluster_indices, local_clusters): # We add total_clusters to ensure each cluster ID is globally unique. all_local_clusters[original_idx] local_cluster_ids total_clusters total_clusters n_local_clusters # Return the final, globally unique cluster assignments for each document. return all_local_clusters最终我们将所有原始叶节点和所有层级的摘要全部索引到同一个向量数据库中。当用户发起查询时例如“如何用PEFT和Accelerate库进行分布式训练”RAPTOR的检索器会检索到包含“分布式训练”高层概念的摘要。同时也会检索到与“PEFT”和“Accelerate”相关的具体代码示例和API说明即叶节点。这种“高层概括”与“底层细节”的完美结合让RAPTOR能够给LLM提供一个既有全局观又有具体细节的上下文。当LLM看到这样的上下文时它能更容易地生成一个结构清晰、内容完整且连贯的答案而不是东拼西凑的零散事实。七、未来展望与总结一场RAG的革命RAPTOR管道代表了RAG领域的一个重要趋势从简单的“检索”走向更深度的“知识组织”。它告诉我们仅仅将文档切块并向量化是不够的我们必须像人一样主动地对知识进行分类、摘要和层次化组织才能真正释放LLM的潜力。虽然RAPTOR需要在构建索引时进行额外的计算比如多次调用LLM进行摘要以及执行复杂的聚类算法但它带来的回报是巨大的在查询时可以显著减少检索到的文档块数量从而节省大量的 Token 消耗并获得更优越的回答质量。这意味着在长远的生产环境中它将带来更高的效率和更低的成本。RAPTOR的成功也为我们带来了更多思考我们能否将这种“递归抽象”的思想应用于更多领域比如能否用它来组织企业的内部文档库让新员工能快速找到从宏观战略到具体操作的全部信息RAPTOR管道能否与其他RAG优化技术如查询转换、重排结合创造出更强大的“超级RAG”毫无疑问RAPTOR不仅仅是一个技术它是一种全新的思维方式正在引领下一代RAG的发展。你认为RAPTOR 的出现会给你的日常工作或学习带来哪些改变八、如何学习AI大模型大模型时代火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业”“谁的饭碗又将不保了”等问题热议不断。不如成为「掌握AI工具的技术人」毕竟AI时代谁先尝试谁就能占得先机想正式转到一些新兴的 AI 行业不仅需要系统的学习AI大模型。同时也要跟已有的技能结合辅助编程提效或上手实操应用增加自己的职场竞争力。但是LLM相关的内容很多现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学学习成本和门槛很高那么针对所有自学遇到困难的同学们我帮大家系统梳理大模型学习脉络将这份LLM大模型资料分享出来包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 有需要的小伙伴可以扫描下方二维码领取↓↓↓学习路线第一阶段 从大模型系统设计入手讲解大模型的主要方法第二阶段 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用第三阶段 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统第四阶段 大模型知识库应用开发以LangChain框架为例构建物流行业咨询智能问答系统第五阶段 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型第六阶段 以SD多模态大模型为主搭建了文生图小程序案例第七阶段 以大模型平台应用与开发为主通过星火大模型文心大模型等成熟大模型构建大模型行业应用。学会后的收获• 基于大模型全栈工程实现前端、后端、产品经理、设计、数据分析等通过这门课可获得不同能力• 能够利用大模型解决相关实际项目需求 大数据时代越来越多的企业和机构需要处理海量数据利用大模型技术可以更好地处理这些数据提高数据分析和决策的准确性。因此掌握大模型应用开发技能可以让程序员更好地应对实际项目需求• 基于大模型和企业数据AI应用开发实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能 学会Fine-tuning垂直训练大模型数据准备、数据蒸馏、大模型部署一站式掌握• 能够完成时下热门大模型垂直领域模型训练能力提高程序员的编码能力 大模型应用开发需要掌握机器学习算法、深度学习框架等技术这些技术的掌握可以提高程序员的编码能力和分析能力让程序员更加熟练地编写高质量的代码。1.AI大模型学习路线图2.100套AI大模型商业化落地方案3.100集大模型视频教程4.200本大模型PDF书籍5.LLM面试题合集6.AI产品经理资源合集获取方式有需要的小伙伴可以保存图片到wx扫描二v码免费领取【保证100%免费】