2026/1/19 8:23:51
网站建设
项目流程
怎么做点击文字进入的网站,有专门做市场分析的网站么,wordpress安装程序,微信上登录网站同步怎么做多智能体系统#xff08;MAS#xff09;的概念在分布式计算领域已经存在数十年了。然而#xff0c;大型语言模型#xff08;LLMs#xff09;和智能体人工智能的出现#xff0c;使得智能体能够在以前无法实现的规模上进行推理、规划和协作。
一、多智能体架构
一个多智能体…多智能体系统MAS的概念在分布式计算领域已经存在数十年了。然而大型语言模型LLMs和智能体人工智能的出现使得智能体能够在以前无法实现的规模上进行推理、规划和协作。一、多智能体架构一个多智能体系统就是多个独立实体智能体的集合这些实体通过协作——有时也通过竞争——来解决复杂问题。每个智能体都能够观察周围环境、做出决策并执行行动且常常会与其他智能体展开协作。这些系统不再仅存在于研究实验室中。它们出现在生产级应用程序中例如• 自动研究助手能够读取、总结和交叉引用数据。• 人工智能驱动的操作副驾驶可以监控基础设施、识别问题并发起变更。• 自主交易系统能同时执行多种策略并交换研究结果。• 多角色客户支持机器人会将咨询分配给专业的人工智能智能体以实现更快的回复。为什么智能体人工智能是变革性力量传统的多智能体系统设计需要硬编码逻辑、严格的程序和大量的手动设置。而智能体人工智能允许每个智能体利用以下能力•推理能力大型语言模型可以容忍不明确的输入仍然生成有意义的行动。•情境感知记忆系统使智能体能够从先前的交互中学习。•智能体间通信能让智能体动态地讨论它们的目标、限制和更新情况。•自我改进循环使智能体能够检查并根据自身表现进行调整 。智能体人工智能的核心概念在编写代码之前你必须了解多智能体系统的基础知识。这些概念将影响你的架构设计、框架选择以及在整个生产过程中智能体的交互方式。智能体、自主性和目标智能体是一个自包含单元它能通过API、数据库、传感器数据等感知其环境处理输入进行推理、推断、决策在环境中采取行动触发工作流程、更新系统、进行通信。自主性意味着智能体可以在没有人类持续监督的情况下运行。它们不会遵循固定的脚本而是适应不断变化的输入根据自身目标做出决策从反馈循环中学习。如何定义智能体让我们看看如何使用LangChain在Python中定义一个智能体。from langchain.agents import initialize_agent, Tool from langchain.llms import OpenAI # 智能体的示例工具 def search_tool(query: str) - str: return fSearching for: {query}... tools [ Tool(nameSearch, funcsearch_tool, descriptionSearches the web for information.) ] llm OpenAI(temperature0, api_key sk-projxxxxxxxxxxxxxxxxxxxx) agent initialize_agent(tools, llm, agentzero-shot-react-description, verboseTrue) agent.run(Find the latest AI research on multi-agent systems.)在进入创建这些强大智能体的下一个阶段之前让我们先了解一下现有的多种智能体类型。3.智能体类型虽然所有智能体都有一个共同的目标但它们的行动和思考方式有所不同。类型描述适用场景反应式智能体直接对输入做出反应无记忆或规划诸如响应状态检查之类的简单任务慎思式智能体使用推理、规划通常具有长期记忆研究助手、决策机器人混合式智能体兼具反应式的速度和慎思式的推理能力需要快速反应和规划的复杂工作流程我的基本建议是尝试使用混合式智能体它完美融合了反应式和慎思式智能体的特点。混合式智能体在速度和灵活性之间取得了平衡使其成为生产环境的最佳选择。通信与协调在实际生产中智能体很少单独运行。通信策略包括智能体之间的直接API调用消息队列如RabbitMQ、Kafka、Pub/Sub实现解耦和可扩展的协调用于知识交换的共享内存存储库例如Redis和向量数据库。记忆和长期情境管理记忆将智能体从无状态函数转变为有状态的问题解决者。多智能体系统中的记忆类型包括短期记忆为当前任务提供情境长期记忆指的是在不同会话之间持久存在的知识情景记忆——用于故障排除和学习的先前交互记录。让我们看看如何在智能体架构中初始化记忆。from langchain.vectorstores import FAISS from langchain.embeddings.openai import OpenAIEmbeddings embeddings OpenAIEmbeddings() memory_store FAISS.from_texts([Hello world, Agentic AI is powerful], embeddings) results memory_store.similarity_search(Tell me about AI, k1) print(results)这份完整版的大模型 AI 学习和面试资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】二、设计多智能体系统构建一个适用于生产环境的多智能体系统不仅仅是将大型语言模型的调用串联起来。从一开始你就必须考虑职责划分、通信方式、容错能力、监控手段和可扩展性。设计理念模块化、可扩展、可互操作在创建多智能体系统时每个智能体都应该可以在不干扰系统其余部分的情况下进行替换系统应该能够在不需要重新设计的情况下管理更多的智能体或任务智能体应该使用通用的API或协议进行交互以便于集成。建议做法避免硬编码智能体依赖项。使用服务注册表或配置文件来指定可用的智能体。定义智能体角色和职责多智能体系统最关键的方面是为每个智能体明确职责这可以避免职责重叠或冲突。角色职责规划智能体分解任务并分配给其他智能体研究智能体从API、数据库或网络收集数据分析智能体处理和解释收集到的数据执行智能体在实际系统中执行操作例如部署代码、触发警报监督智能体监控、验证输出并处理异常以下是一个基于角色的智能体配置示例agents: planner: description: Breaks tasks into sub-tasks and delegates. tools: [task_router, status_tracker] researcher: description: Finds and retrieves relevant information. tools: [web_search, api_fetch] analyzer: description: Interprets and summarizes research findings. tools: [nlp_analysis, data_visualization]选择通信协议在生产环境中智能体之间的通信方式对于速度、可靠性和规模至关重要。直接函数调用简单但智能体耦合紧密适用于本地原型消息代理如RabbitMQ、Kafka、Pub/Sub解耦、异步且可扩展HTTP/gRPC API适用于在多个平台上运行并使用微服务的智能体WebSocket提供实时双向通信。以下是通过Pub/Sub进行消息传递的示例import json from google.cloud import pubsub_v1 publisher pubsub_v1.PublisherClient() topic_path projects/my-project/topics/agent-messages message_data json.dumps({task: fetch_data, params: {query: AI news}}).encode(utf-8) publisher.publish(topic_path, message_data)任务分解与编排可以通过两种方式安排多智能体系统的编排。分层式——任务由中央控制器分配去中心化——智能体围绕共同目标自组织。建议做法分层式编排便于日志记录和调试而去中心化编排在动态环境中表现更好。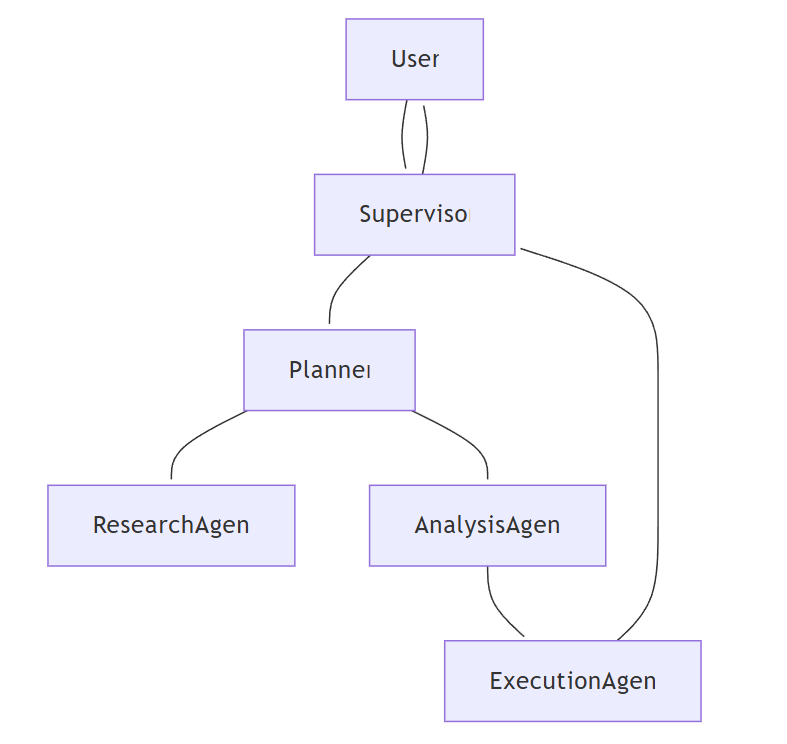工具、框架和技术栈你所使用的工具将对多智能体系统产生重大影响。在生产环境中正确的技术栈可确保系统的可扩展性、可维护性和成本管理。智能体框架框架可避免你在编排、消息传递和记忆处理方面重复造轮子。框架语言优势理想用例LangChainPython/JS工具集成、提示编排、记忆处理快速构建复杂工作流程AutoGenPython多智能体聊天、智能体间消息传递便捷对话式多智能体系统的快速原型开发CrewAIPython角色/任务分配、智能体协作专注于任务的自治团队OpenDevinPythonDevOps和智能体编码自动化人工智能辅助代码部署AgentVersePython模拟、角色扮演智能体研究和实验性多智能体系统建议不要仅仅依赖于一个框架。你可以混合使用例如使用Langchain进行工具和记忆处理使用AutoGen进行消息传递。大型语言模型和基础模型选择大型语言模型时要基于多种因素包括成本、速度、可靠性和准确性。以下是一些可供参考的选择模型优势劣势适用场景GPT-4o推理能力强、多模态成本高、比小型模型慢复杂规划智能体Claude 3.5 Sonnet总结能力强、输出安全代码执行推理能力有限研究和分析智能体Mistral 7B速度快、开源、成本低深度推理能力较弱高流量反应式智能体LLaMA 3 70B开源推理能力强需要GPU基础设施私有内部多智能体系统对于生产需求我强烈建议采用混合技术例如可以使用像LLaMa 3.1 7B或Qwen 1B这样的小型模型进行过滤和分类使用像GPT-5、GPT-4o系列、LLaMa 4系列这样的大型模型来处理复杂挑战。记忆、向量存储和嵌入智能体需要记忆才能在单个任务之外发挥作用。以下是一些常用的选择FAISS是一个轻量级向量存储完全在内存中运行Chroma支持本地和云存储与LangChain无缝连接Weaviate可扩展、云原生支持混合搜索Pinecone托管式服务、速度快但大规模使用可能成本较高。让我们看看如何使用Langchain处理记忆from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import FAISS embeddings OpenAIEmbeddings() db FAISS.from_texts([Agentic AI is awesome, Multi-agent systems scale work], embeddings) print(db.similarity_search(Tell me about AI agents, k1))通信中间件通信层对于多智能体编排至关重要。以下是一些常见的选择Pub/Sub谷歌、Kafka——异步且适用于大规模场景Redis Streams——轻量级且速度快WebSocket实时双向通信HTTP/gRPC与微服务可互操作。对于多云或混合系统建议使用gRPC它提供了可靠且高效的通信方式。部署栈在生产环境中后端可使用FastAPI、Flask或Node.js作为API端点使用Docker进行容器化以实现可移植性使用Kubernetes进行智能体的扩展编排使用Prometheus Grafana或OpenTelemetry进行监控使用GitHub Actions、Jenkins或GitLab CI进行持续集成/持续交付CI/CD。生产架构可能如下所示构建你的第一个多智能体系统让我们看看如何开发一个包含三个智能体的系统。规划智能体负责将任务分解为子任务研究智能体负责收集和整理信息总结智能体负责为最终用户提炼研究结果。我们还将集成Pub/Sub消息传递进行通信使用FAISS向量存储进行记忆处理使用OpenAI GPT-4o进行推理。步骤1——定义用例我们将构建一个“研究与总结”多智能体系统用户请求一个主题→规划智能体确定子主题→研究智能体收集信息→总结智能体将其浓缩为最终输出。步骤2——选择智能体角色和提示我们将角色和基本提示保存在YAML配置中这样无需修改代码即可进行更新。agents: planner: role: Break tasks into subtasks prompt: Given a user query, list 3–5 research subtopics. researcher: role: Gather info for each subtopic prompt: Search and retrieve concise, factual info on: {subtopic} summarizer: role: Summarize all research prompt: Summarize the following research into an easy-to-read format.步骤3——建立通信这里我们使用谷歌的Sub/Pub进行异步消息传递。以下是使用发布者向智能体发送任务的示例import json from google.cloud import pubsub_v1 publisher pubsub_v1.PublisherClient() topic_path projects/my-project/topics/agent-tasks def send_task(agent, payload): data json.dumps({agent: agent, payload: payload}).encode(utf-8) publisher.publish(topic_path, data)以下是订阅者接收信息智能体接收任务的方式from google.cloud import pubsub_v1 subscriber pubsub_v1.SubscriberClient() subscription_path projects/my-project/subscriptions/planner-sub def callback(message): print(fReceived task: {message.data}) message.ack() subscriber.subscribe(subscription_path, callbackcallback)步骤4——实现任务路由和反馈规划智能体将子任务发送给研究智能体研究智能体将结果返回给总结智能体。智能体逻辑如下from langchain.llms import OpenAI llm OpenAI(modelgpt-4o, temperature0) def plan_research(query): prompt fBreak this down into 3-5 subtopics: {query} subtopics llm.predict(prompt).split(\n) for topic in subtopics: send_task(researcher, {subtopic: topic})步骤5——集成记忆我们将使用FAISS为总结智能体存储检索到的研究内容。from langchain.vectorstores import FAISS from langchain.embeddings.openai import OpenAIEmbeddings embeddings OpenAIEmbeddings() db FAISS.from_texts([], embeddings) def save_research(subtopic, text): db.add_texts([f{subtopic}: {text}]) def retrieve_all(): return \n.join([doc.page_content for doc in db.similarity_search(, k50)])步骤6——部署和测试将每个智能体进行容器化使其能够独立运行使用Kubernetes根据负载扩展研究智能体设置日志记录例如Stackdriver、ELK Stack以跟踪消息流监控Pub/Sub延迟和FAISS搜索性能。Dockerfile内容如下FROM python:3.11 WORKDIR /app COPY . /app RUN pip install -r requirements.txt CMD [python, agent.py]三、结论从蓝图到生产多智能体系统不再仅仅是学术概念——它们正在成为下一代人工智能应用的支柱。通过结合大型语言模型进行推理、明确的智能体角色分工、强大的通信渠道和可扩展的部署栈开发者可以构建出真正能够实时协作和自适应的生产级系统。在本文中我们探讨了自主性、智能体类型、记忆和通信的核心概念确保模块化、可扩展性和互操作性的架构原则加速开发的实用框架和技术栈一个从YAML配置到Pub/Sub消息传递、FAISS记忆处理和容器化部署的研究与总结多智能体系统的实践实现。核心要点很简单多智能体设计并非过多涉及复杂理论而更多在于深思熟虑的工程选择。从小处着手比如我们构建的三智能体系统衡量性能然后通过更多专业智能体、通信层和编排策略进行迭代。接下来你可以做什么• 尝试不同的框架如LangChain、AutoGen、CrewAI并比较权衡。• 为你的多智能体系统引入监控和自我改进循环以增强稳健性。• 通过引入Kubernetes、gRPC和高级内存存储逐步扩展到生产环境。智能体人工智能的时代才刚刚开始——通过了解如何设计、协调和扩展这些系统你正在为未来最强大的应用程序奠定基础。四、如何学习AI大模型如果你对AI大模型入门感兴趣那么你需要的话可以点击这里大模型重磅福利入门进阶全套104G学习资源包免费分享这份完整版的大模型 AI 学习和面试资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】这是一份大模型从零基础到进阶的学习路线大纲全览小伙伴们记得点个收藏第一阶段从大模型系统设计入手讲解大模型的主要方法第二阶段在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用第三阶段大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统第四阶段大模型知识库应用开发以LangChain框架为例构建物流行业咨询智能问答系统第五阶段大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型第六阶段以SD多模态大模型为主搭建了文生图小程序案例第七阶段以大模型平台应用与开发为主通过星火大模型文心大模型等成熟大模型构建大模型行业应用。100套AI大模型商业化落地方案大模型全套视频教程200本大模型PDF书籍学会后的收获• 基于大模型全栈工程实现前端、后端、产品经理、设计、数据分析等通过这门课可获得不同能力• 能够利用大模型解决相关实际项目需求 大数据时代越来越多的企业和机构需要处理海量数据利用大模型技术可以更好地处理这些数据提高数据分析和决策的准确性。因此掌握大模型应用开发技能可以让程序员更好地应对实际项目需求• 基于大模型和企业数据AI应用开发实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能 学会Fine-tuning垂直训练大模型数据准备、数据蒸馏、大模型部署一站式掌握• 能够完成时下热门大模型垂直领域模型训练能力提高程序员的编码能力 大模型应用开发需要掌握机器学习算法、深度学习框架等技术这些技术的掌握可以提高程序员的编码能力和分析能力让程序员更加熟练地编写高质量的代码。LLM面试题合集大模型产品经理资源合集大模型项目实战合集获取方式有需要的小伙伴可以保存图片到wx扫描二v码免费领取【保证100%免费】