2026/1/17 13:35:00
网站建设
项目流程
网站屏蔽右键破解,电器网站建设策划书,食品网站建设实施方案,如何注册网络公司目录问题1#xff1a;问题链接#xff1a;问题描述#xff1a;实例#xff1a;代码#xff1a;问题2#xff1a;问题链接#xff1a;问题描述#xff1a;实例#xff1a;代码#xff1a;问题3#xff1a;问题链接#xff1a;问题描述#xff1a;实例#xff1a;问…目录问题1问题链接问题描述实例代码问题2问题链接问题描述实例代码问题3问题链接问题描述实例问题4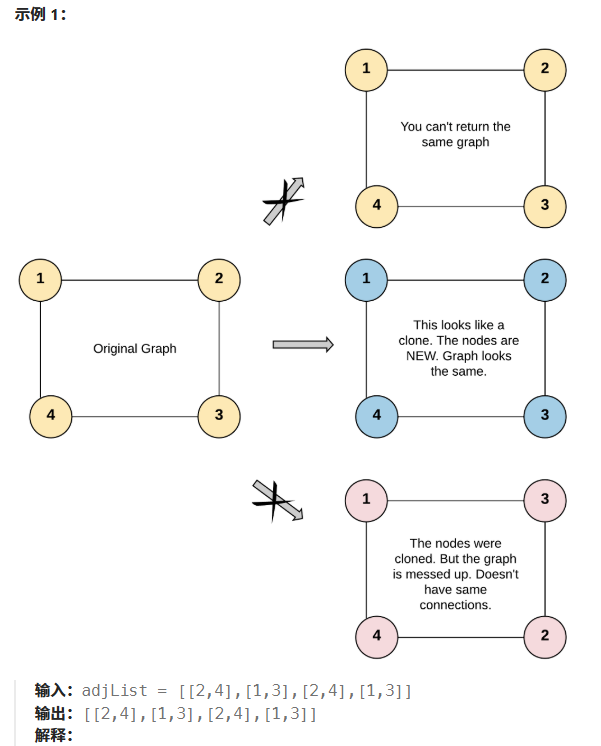代码问题4问题链接问题描述实例代码问题5问题链接问题描述实例代码问题6问题链接问题描述实例代码问题7问题链接问题描述实例代码问题8问题链接问题描述实例代码问题9问题链接问题描述实例代码问题10问题链接问题描述实例代码问题1问题链接131. 分割回文串问题描述给你一个字符串 s请你将 s 分割成一些 子串使每个子串都是 回文串 。返回 s 所有可能的分割方案。实例示例1 输入saab 输出[[a,a,b],[aa,b]]示例2 输入sa 输出[[a]]代码回溯#输入的视角classSolution:defpartition(self,s:str)-List[List[str]]:nlen(s)ans[]path[]# 考虑 i 后面的逗号怎么选# start 表示当前这段回文子串的开始位置defdfs(i:int,start:int)-None:ifin:# s 分割完毕ans.append(path.copy())# 复制 pathreturn# 不分割不选 i 和 i1 之间的逗号ifin-1:# in-1 时只能分割# 考虑 i1 后面的逗号怎么选dfs(i1,start)# 分割选 i 和 i1 之间的逗号把 s[i] 作为子串的最后一个字符ts[start:i1]iftt[::-1]:# 判断是否回文path.append(t)# 考虑 i1 后面的逗号怎么选# starti1 表示下一个子串从 i1 开始dfs(i1,i1)path.pop()# 恢复现场dfs(0,0)returnans#答案的视角classSolution:defpartition(self,s:str)-List[List[str]]:nlen(s)ans[]path[]# 考虑 s[i:] 怎么分割defdfs(i:int)-None:ifin:# s 分割完毕ans.append(path.copy())# 复制 pathreturnforjinrange(i,n):# 枚举子串的结束位置ts[i:j1]# 分割出子串 tiftt[::-1]:# 判断 t 是不是回文串path.append(t)# 考虑剩余的 s[j1:] 怎么分割dfs(j1)path.pop()# 恢复现场dfs(0)returnans问题2问题链接132. 分割回文串 II问题描述给你一个字符串 s请你将 s 分割成一些子串使每个子串都是回文串。 返回符合要求的 最少分割次数 。实例示例1 输入saab 输出1解释只需一次分割就可将 s 分割成[aa,b]这样两个回文子串。 示例2 输入sa 输出0示例3 输入sab 输出1代码记忆化搜索classSolution:defminCut(self,s:str)-int:# 返回 s[l:r1] 是否为回文串cache# 缓存装饰器避免重复计算 is_palindrome一行代码实现记忆化defis_palindrome(l:int,r:int)-bool:iflr:returnTruereturns[l]s[r]andis_palindrome(l1,r-1)cache# 缓存装饰器避免重复计算 dfs一行代码实现记忆化defdfs(r:int)-int:ifis_palindrome(0,r):# 已是回文串无需分割return0resinfforlinrange(1,r1):# 枚举分割位置ifis_palindrome(l,r):resmin(res,dfs(l-1)1)# 在 l-1 和 l 之间切一刀returnresreturndfs(len(s)-1)问题3问题链接133. 克隆图问题描述给你无向 连通 图中一个节点的引用请你返回该图的 深拷贝克隆。 图中的每个节点都包含它的值 valint 和其邻居的列表list[Node]。 class Node{public int val;public ListNodeneighbors;}测试用例格式 简单起见每个节点的值都和它的索引相同。例如第一个节点值为1val1第二个节点值为2val2以此类推。该图在测试用例中使用邻接列表表示。 邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。 给定节点将始终是图中的第一个节点值为1。你必须将 给定节点的拷贝 作为对克隆图的引用返回。实例问题4代码 # Definition for a Node. class Node: def __init__(self, val 0, neighbors None): self.val val self.neighbors neighbors if neighbors is not None else [] #1.偷懒做法fromtypingimportOptionalclassSolution:defcloneGraph(self,node:Optional[Node])-Optional[Node]:returncopy.deepcopy(node)#广搜fromtypingimportOptionalclassSolution:defcloneGraph(self,node:Optional[Node])-Optional[Node]:ifnotnode:returnNone# 空节点不拷贝clone_nodes{node.val:Node(node.val)}# 存储每一个拷贝过的节点并克隆起点节点queue[node]# 用于广度优先搜索的队列且起点节点入队whilequeue:curqueue.pop(0)# 从队列中获取一个待处理的节点clone_nodeclone_nodes[cur.val]# 待处理的节点一定是克隆好了的直接获取其克隆节点forneighborincur.neighbors:# 处理当前节点的邻接节点ifneighbor.valnotinclone_nodes:clone_nodes[neighbor.val]Node(neighbor.val)# 如果邻接节点未拷贝则拷贝queue.append(neighbor)# 未拷贝的节点说明还没有处理加入队列等待处理clone_node.neighbors.append(clone_nodes[neighbor.val])# 将邻接节点的拷贝节点加入当前节点的拷贝节点的邻接列表returnclone_nodes[node.val]# 返回起点节点的克隆节点#深搜fromtypingimportOptionalclassSolution:def__init__(self):self.clone_nodes{}# 存储每一个克隆过的节点defcloneGraph(self,node:Optional[Node])-Optional[Node]:ifnotnode:returnNone# 空节点不克隆ifnode.valinself.clone_nodes:returnself.clone_nodes[node.val]# 克隆了的节点不重复克隆clone_nodeNode(node.val)# 创建一个克隆后的节点self.clone_nodes[node.val]clone_node# 存储克隆节点forneighborinnode.neighbors:# 克隆节点 克隆 被克隆节点的邻接列表clone_node.neighbors.append(self.cloneGraph(neighbor))returnclone_node问题4问题链接134. 加油站问题描述在一条环路上有 n 个加油站其中第i个加油站有汽油 gas[i]升。 你有一辆油箱容量无限的的汽车从第i个加油站开往第i1个加油站需要消耗汽油 cost[i]升。你从其中的一个加油站出发开始时油箱为空。 给定两个整数数组 gas 和 cost 如果你可以按顺序绕环路行驶一周则返回出发时加油站的编号否则返回-1。如果存在解则 保证 它是 唯一 的。实例示例1:输入:gas[1,2,3,4,5],cost[3,4,5,1,2]输出:3解释:从3号加油站(索引为3处)出发可获得4升汽油。此时油箱有044升汽油 开往4号加油站此时油箱有4-158升汽油 开往0号加油站此时油箱有8-217升汽油 开往1号加油站此时油箱有7-326升汽油 开往2号加油站此时油箱有6-435升汽油 开往3号加油站你需要消耗5升汽油正好足够你返回到3号加油站。 因此3可为起始索引。 示例2:输入:gas[2,3,4],cost[3,4,3]输出:-1解释:你不能从0号或1号加油站出发因为没有足够的汽油可以让你行驶到下一个加油站。 我们从2号加油站出发可以获得4升汽油。 此时油箱有044升汽油 开往0号加油站此时油箱有4-323升汽油 开往1号加油站此时油箱有3-333升汽油 你无法返回2号加油站因为返程需要消耗4升汽油但是你的油箱只有3升汽油。 因此无论怎样你都不可能绕环路行驶一周。代码classSolution:defcanCompleteCircuit(self,gas:List[int],cost:List[int])-int:ansmin_ss0#s为油量min_s表示最小油量fori,(g,c)inenumerate(zip(gas,cost)):sg-cifsmin_s:min_ss# 更新最小油量ansi1# 注意 s 减去 c 之后汽车在 i1 而不是 ireturn-1ifs0elseans问题5问题链接135. 分发糖果问题描述n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。 你需要按照以下要求给这些孩子分发糖果 每个孩子至少分配到1个糖果。 相邻两个孩子中评分更高的那个会获得更多的糖果。 请你给每个孩子分发糖果计算并返回需要准备的 最少糖果数目 。实例示例1 输入ratings[1,0,2]输出5解释你可以分别给第一个、第二个、第三个孩子分发2、1、2颗糖果。 示例2 输入ratings[1,2,2]输出4解释你可以分别给第一个、第二个、第三个孩子分发1、2、1颗糖果。 第三个孩子只得到1颗糖果这满足题面中的两个条件。代码classSolution:defcandy(self,ratings:List[int])-int:left[1for_inrange(len(ratings))]rightleft[:]foriinrange(1,len(ratings)):ifratings[i]ratings[i-1]:left[i]left[i-1]1countleft[-1]foriinrange(len(ratings)-2,-1,-1):ifratings[i]ratings[i1]:right[i]right[i1]1countmax(left[i],right[i])returncount问题6问题链接136. 只出现一次的数字问题描述给你一个 非空 整数数组 nums 除了某个元素只出现一次以外其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题且该算法只使用常量额外空间。实例示例1 输入nums[2,2,1]输出1示例2 输入nums[4,1,2,1,2]输出4示例3 输入nums[1]输出1代码#使用哈希classSolution:defsingleNumber(self,nums:List[int])-int:count_nCounter(nums)forkey,valueincount_n.items():ifvalue1:returnkey问题7问题链接137. 只出现一次的数字 II问题描述给你一个整数数组 nums 除某个元素仅出现 一次 外其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法且使用常数级空间来解决此问题。实例示例1 输入nums[2,2,3,2]输出3示例2 输入nums[0,1,0,1,0,1,99]输出99代码classSolution:defsingleNumber(self,nums:List[int])-int:ones,twos0,0fornuminnums:onesones^num~twos twostwos^num~onesreturnones问题8问题链接138. 随机链表的复制问题描述给你一个长度为 n 的链表每个节点包含一个额外增加的随机指针 random 该指针可以指向链表中的任何节点或空节点。 构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。 例如如果原链表中有 X 和 Y 两个节点其中 X.random--Y 。那么在复制链表中对应的两个节点 x 和 y 同样有 x.random--y 。 返回复制链表的头节点。 用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val,random_index]表示 val一个表示 Node.val 的整数。 random_index随机指针指向的节点索引范围从0到 n-1如果不指向任何节点则为 null 。 你的代码 只 接受原链表的头节点 head 作为传入参数。实例代码 # Definition for a Node. class Node: def __init__(self, x: int, next: Node None, random: Node None): self.val int(x) self.next next self.random random classSolution:defcopyRandomList(self,head:Node)-Node:ifnothead:returnhead# 复制所有节点插入原节点的后面curheadwhilecur:cur.nextNode(cur.val,cur.next,None)curcur.next.next# 连接所有复制的节点的random指针curhead copyHeadhead.nextwhilecur:ifcur.random:cur.next.randomcur.random.nextcurcur.next.next# 断开原链表与复制链表之间的连接curhead cur_copyHeadwhilecurandcur_:cur.nextcur_.nextcurcur.nextifcur:cur_.nextcur.nextcur_cur_.nextreturncopyHead问题9问题链接139. 单词拆分问题描述给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意不要求字典中出现的单词全部都使用并且字典中的单词可以重复使用。实例示例1 输入:sleetcode,wordDict[leet,code]输出:true 解释:返回 true 因为 leetcode 可以由 leet 和 code 拼接成。 示例2 输入:sapplepenapple,wordDict[apple,pen]输出:true 解释:返回 true 因为 applepenapple 可以由 apple pen apple 拼接成。 注意你可以重复使用字典中的单词。 示例3 输入:scatsandog,wordDict[cats,dog,sand,and,cat]输出:false代码classSolution:defwordBreak(self,s:str,wordDict:List[str])-bool:nlen(s)cachedefdfs(i):ifin:returnTrueforjinrange(i1,n1):ifs[i:j]inwordDictanddfs(j):returnTruereturnFalsereturndfs(0)问题10问题链接140. 单词拆分 II问题描述给定一个字符串 s 和一个字符串字典 wordDict 在字符串 s 中增加空格来构建一个句子使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。 注意词典中的同一个单词可能在分段中被重复使用多次。实例示例1 输入:scatsanddog,wordDict[cat,cats,and,sand,dog]输出:[cats and dog,cat sand dog]示例2 输入:spineapplepenapple,wordDict[apple,pen,applepen,pine,pineapple]输出:[pine apple pen apple,pineapple pen apple,pine applepen apple]解释:注意你可以重复使用字典中的单词。 示例3 输入:scatsandog,wordDict[cats,dog,sand,and,cat]输出:[]代码classSolution:# 超时defwordBreak(self,s:str,wordDict:List[str])-List[str]:res[]#wordDictset(wordDict)defdfs(wordDict,temp,pos):#ifposlen(s):res.append( .join(temp))returnforiinrange(pos,len(s)1):ifs[pos:i]inwordDict:temp.append(s[pos:i])dfs(wordDict,temp,i)temp.pop()#dfs(wordDict,[],0)returnres